Sorry for not responding earlier to this. Have been a bit busy this week.
Unlimted timeframe and interval
@Pectojin and @kees-z
I’ve read through your discussion and thought about it for quite a while.
I quite like your idea of having U for „Unlimited“ for both the timeframe and the interval. So you could for example have 1W:U,1Y:1W,U:1M:
1W:Uwould mean “For one week keep all (=unlimited) versions”. Internally it’ll work the same as specifying0sfor the intervall and0swill still be valid as interval for this functionality.1Y:1Wstill means “For one year keep a version at the interval of one week”. No change here in how it works.U:1Mwould mean “For unlimited time keep a version at the interval of one month". This could replace the need for having to specify a very long timeframe like99Y. It’ll always be applied after the last rule, so for example if you also have an99Y:2Wtimeframe, then that one will be used before theU:1Mtimeframe.
(Internally the unllimited timeframe will still work with a specific date of January 1st, 0001, see DateTim.MinValue)
Minimum numer of backups to keep
As for the idea to keep a minimum amount of versions, I’m still quite sceptical, especially since it’s a bit hard for me to understand why having a certain amount of backups supposedly results in a “safer” situation. IMHO this somewhat goes against what the retention policy is supposed to do, that is, deleting outdated backups and keeping the backup list short-ish, while still keeping frequent backups of recent changes.
But ok, that is only my humble opinion. I tried to show some pitfalls in the following example:
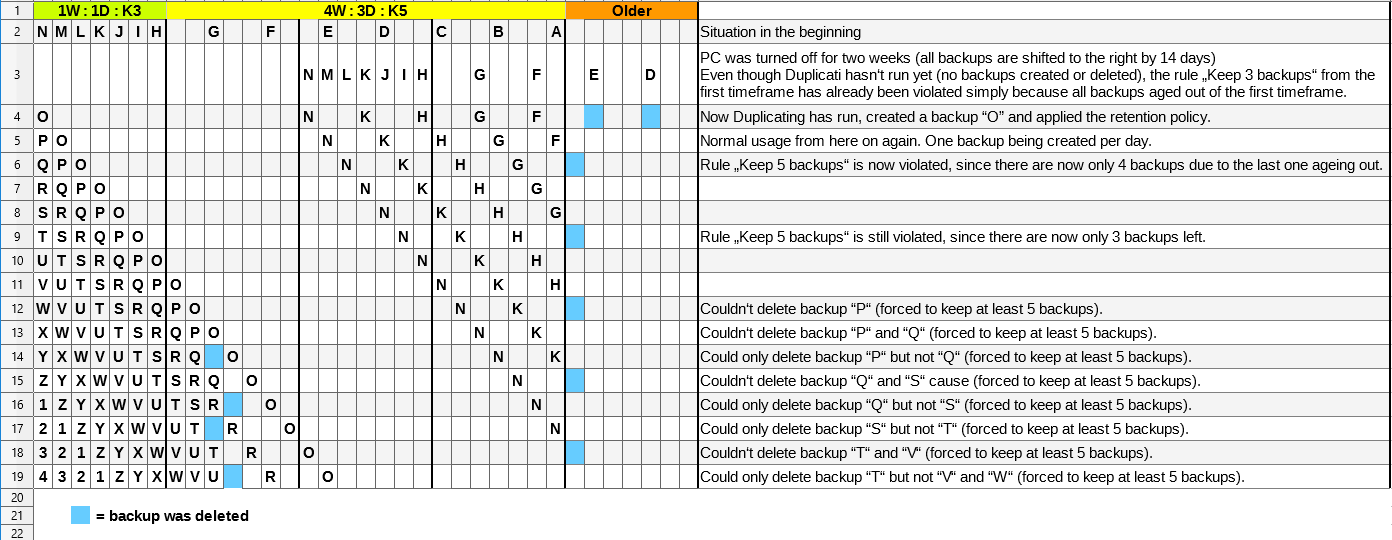
Here the two timeframes now have the proposed new K:X rule for keeping a minumum number of backups per timeframe (see row 1). But with these “Keep” rules per timeframe Duplicati would:
- still keep less backups if no backups have been created for a while e.g. user is gone or source data wasn’t modified so Duplicati didn’t create backups (see row 3 and 6)
- suddenly violate the retention policy and stop deleting backups even thought there are already quite a lot more recent backups (see row 12 and onwards).
What might work slightly better is to define a global, timeframe-independent “Keep” rule which overrules some of the decisions the retention policy made. But this then conflicts with the new “Unlimited” timeframe rule from above. For example a user might specify K:10 and U:1M. Then, after 10 months, he will have accumulated 10 backups and since these don’t get deleted, he will always have 10 or more backups from now on, rendering the K:10 useless for protecting newer backups after long absence.
Also this global “Keep” rule might be confusing as to how it differs from the --keep-versions option.
Logging with level Information
That’s because the log messages are logged with the priority Information in the code. If you’d set --log-level=Profiling and a log file via --log-file=... then you’d get even more messages from the retention policy run (among other things). These additional messages wont show up in the Messages: [...] output though. I think Duplicati in general limits messages in this area to the level Information and above, maybe to not clutter the output there too much. But I’m not 100% certain about that.
As to why @drakar2007 doesn’t have to specify the level in the options of the backup job: Maybe he has it set to Information globally in the Default options sections of the Settings, so there isn’t any need to set it on a per job basis?