So are you saying all that stuff doesn’t appear in the Result log if you don’t have that setting set? Because it shows up in my logs seemingly regularly.
Yes, No stuff at all about the retention policy appears if I don’t have that setting set. Same thing on all 4 computers which I have Duplicati installed on.
Weird, since I’ve never set that setting AFAIK and yet the retention policy stuff shows up in mine.
Someone else has the problem on latest Canary, I also do. I have backups with retention option “Keep all backups”. Now when I change to the new retention options and save, then re-edit config, it show “Keep all backups”.
But when I look into the export command line view, there it shows it has saved “–retention-policy=“1W:1D,4W:1W,12M:1M””.
The UI is highly confused.
Sorry for not responding earlier to this. Have been a bit busy this week.
Unlimted timeframe and interval
@Pectojin and @kees-z
I’ve read through your discussion and thought about it for quite a while.
I quite like your idea of having U for „Unlimited“ for both the timeframe and the interval. So you could for example have 1W:U,1Y:1W,U:1M:
1W:Uwould mean “For one week keep all (=unlimited) versions”. Internally it’ll work the same as specifying0sfor the intervall and0swill still be valid as interval for this functionality.1Y:1Wstill means “For one year keep a version at the interval of one week”. No change here in how it works.U:1Mwould mean “For unlimited time keep a version at the interval of one month". This could replace the need for having to specify a very long timeframe like99Y. It’ll always be applied after the last rule, so for example if you also have an99Y:2Wtimeframe, then that one will be used before theU:1Mtimeframe.
(Internally the unllimited timeframe will still work with a specific date of January 1st, 0001, see DateTim.MinValue)
Minimum numer of backups to keep
As for the idea to keep a minimum amount of versions, I’m still quite sceptical, especially since it’s a bit hard for me to understand why having a certain amount of backups supposedly results in a “safer” situation. IMHO this somewhat goes against what the retention policy is supposed to do, that is, deleting outdated backups and keeping the backup list short-ish, while still keeping frequent backups of recent changes.
But ok, that is only my humble opinion. I tried to show some pitfalls in the following example:
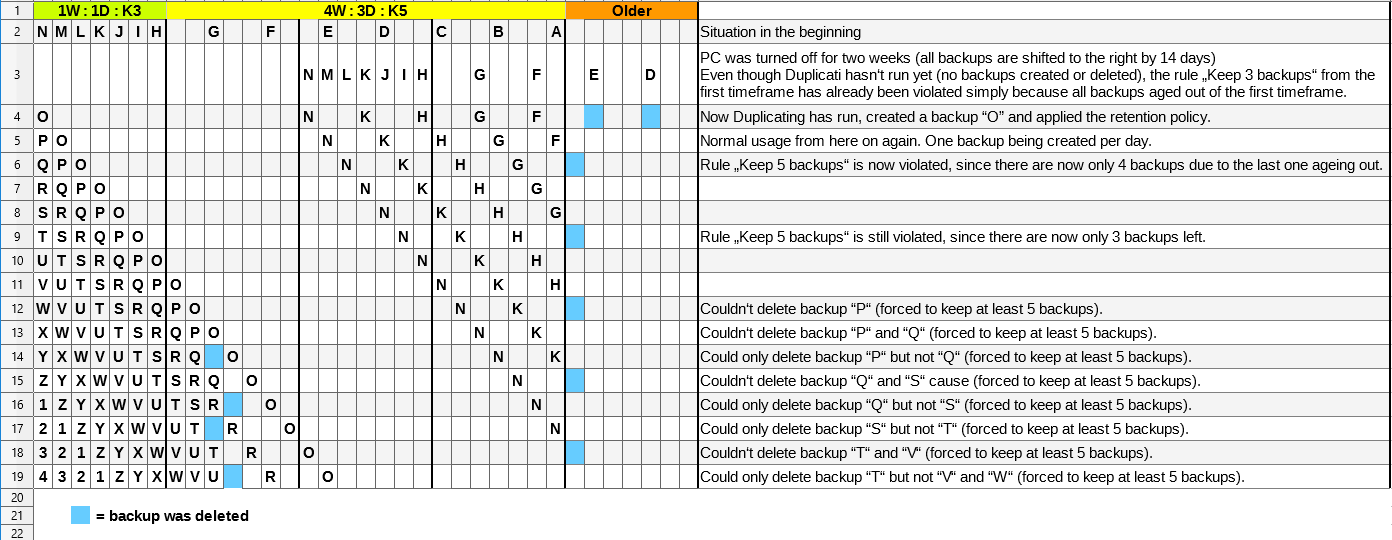
Here the two timeframes now have the proposed new K:X rule for keeping a minumum number of backups per timeframe (see row 1). But with these “Keep” rules per timeframe Duplicati would:
- still keep less backups if no backups have been created for a while e.g. user is gone or source data wasn’t modified so Duplicati didn’t create backups (see row 3 and 6)
- suddenly violate the retention policy and stop deleting backups even thought there are already quite a lot more recent backups (see row 12 and onwards).
What might work slightly better is to define a global, timeframe-independent “Keep” rule which overrules some of the decisions the retention policy made. But this then conflicts with the new “Unlimited” timeframe rule from above. For example a user might specify K:10 and U:1M. Then, after 10 months, he will have accumulated 10 backups and since these don’t get deleted, he will always have 10 or more backups from now on, rendering the K:10 useless for protecting newer backups after long absence.
Also this global “Keep” rule might be confusing as to how it differs from the --keep-versions option.
Logging with level Information
That’s because the log messages are logged with the priority Information in the code. If you’d set --log-level=Profiling and a log file via --log-file=... then you’d get even more messages from the retention policy run (among other things). These additional messages wont show up in the Messages: [...] output though. I think Duplicati in general limits messages in this area to the level Information and above, maybe to not clutter the output there too much. But I’m not 100% certain about that.
As to why @drakar2007 doesn’t have to specify the level in the options of the backup job: Maybe he has it set to Information globally in the Default options sections of the Settings, so there isn’t any need to set it on a per job basis?
4 Likes
So are you saying that having this log level setting is required for retention policy to work?
No, not at all. The log level does have no influence on the actual functionality of the retention policy but rather on what it logs.
Oh, ok. I guess I was used to the way the “advanced option” version of Retention Policy worked, because I was used to seeing my “result” logs reference old backup jobs. I see now that it only mentions old backup sets deleted (“DeletedSets”), but doesn’t mention Retention Policy by name (i have no particular setting set for “log level”, though I might change that now).
Edit: I also just noticed that the “result” log shows the retention policy output if i simply have the information-level live log viewer open during a backup job. That seems a bit weird. I guess just having that log open temporarily changes the -log-level systemwide setting?
Thank you for you detailed explanation.
A few comments:
I suppose almost all users prefer to have a choice between a number of versions when performing a restore operation. If whatever retention policy wipes all backups away except the most recent backup, I guess this is almost always unintended. A K (or something similar) option could prevent this.
At a given starting point, there will (almost) always be less backups than the specified minimum, but this number of backups will increase until there are enough versions. From that moment, the retention policy can start thinning out versions (and stop if there are K remaining versions).
The retention policy is not violated, because the K option is part of it. It just stops deleting versions temporarily, until there are enough (too many) versions.
Agreed, this will always make easier to understand for the end user what actually happens.
To be honest, I don’t see this as a conflict, more as a redundant option.
The K value doesn’t harm when applied to your example, but prevents deleting all versions except one, when using 1M:1D and leaving the computer switched off for more than 30 days (or no change to source files in the last 30 days).
In what way is it different? A global “Keep” rule does exactly the same as --keep-versions, doesn’t it? As the --retention-policy and --keep-versions cannot be combined, a K option could replace --keep-versions when using --retention-policy.
Admitted, in the “pre-Retention Policy era”, --keep-time=30D would have exactly the same symptoms as --retention-policy=30D:1D, so the issue is not introduced with the new --retention-policy option.
1 Like
Hi everyone!
I’m yet another Crashplan refugee who has found Duplicati to be the answer for my needs.
Could you just corfirm that when you say “backups”, you mean “backups of file X” rather than “all the files that were included in a certain run of a backup job”? It guess it works at the file level, but I thought I’d ask…
Also, what would the overhead be on a backup set of several thousand files? Is the retention thingy run every time or at specified intervals? Some of my CP jobs took bleeding forever to do “deep maintenance” once a month…
Sorry if I’m asking any stupid questions, just tell me so and I’ll go away.
Cheers from Oslo,
Kjell
Hello @Pikachu, welcome to the forum! ![]()
To be sure I’m understanding the question, I’d need to know what you’re quoting, but generally a “backup” or “backup set” is ALL of the file versions handled in a single job run.
Note that because of how Duplicati stores versions and deltas, if you delete a backup SET you’re really deleting all the VERSIONS of files that are in that set. If only one version of the file exists, then you’re deleting it completely - otherwise, you should still have other versions that can be restored.
Every time - I believe at the end of the backup job. Depending on your dblock (archive Volume size) and bandwidth you may still find that this cleanup can take a while, but since it’s not a “once a month” thing it shouldn’t be too painful.
I once heard somebody say “There are no stupid questions”…I’m not sure I believe them on that, but yours certainly aren’t so keep 'em coming! ![]()
That’s almost exactly how it works. One note:
If you have one versions of a file, that file will not be deleted when deleting a backup version. The file will be unrecoverable from the moment that the last backup version is deleted that contains that file.
Example:
File1.txt is created on Tuesday on your hard drive and is included in the source folders of Duplicati. The backup runs daily, so if no changes are made to File1.txt, Tuesday and Wednesday contain the same version of File1.txt.
The file is changed after the Wednesday backup is made. The backup versions from Thursday, Friday and Saturday contain the new version of the file.
If backup versions Wednesday, Thursday and Saturday are deleted, both versions of File1.txt can be recovered: Version 1 from Tuesday, version 2 from Friday.
After deleting Tuesday, Version 1 of File1.txt can’t be recovered anymore: Monday doesn’t contain this file, all versions containing Version 1 (Tuesday and Wednesday) are deleted. But Version 2 still can be restored from the Friday backup.
Any version of File1.txt will become unrecoverable after deleting the Friday backup version, assuming that this happens before Sunday. If the Friday version is deleted after the Sunday backup is made, File1.txt can be restored, even after the Friday backup has been deleted: this file is still available in the Sunday backup.
Summarized:
A backup version is a repesentation of how your source files looked like at the moment the that backup was made. Any version of a file will become unrecoverable as soon as all backup versions containing that file version are deleted. Other versions of that file will still be recoverable as long as there is at least one backup version that contains that file version.
2 Likes
I’d note that this creates a potential failure point with respect to an individual file which is accidentally deleted and sufficient time elapses before the deletion is discovered - if its last backed-up version was in one of the jobs that gets pruned by retention, it seems like it will be gone (since retention only pays attention to versions instead of individual files).
That’s why I like to add the “99 years, 1 copy” policy setting. Basically a “keep at least 1 version of everything” policy.
Thought if the “U” (unlimited) type parameter discussed above gets implemented I’d use that.
1 Like
Though does this solve the issue of an accidentally deleted file getting lost when its only backup version(s) are pruned by RP? Per what I’ve seen in discussions before (including from the user who developed it), only backup sets are considered and not individual files - so deleted files will eventually cycle out if they don’t happen to be in the backup version that’s kept in long-term.
Yes. Files or versions that exist very briefly can definitely be lost with retention-policy.
I don’t know that there is a good way to resolve this “version-awareness” since Duplicati is, in essense, version agnostic. I doesn’t care about the versions, just what was in each “snapshot”.
My retention policy assumes that anything I don’t notice losing within a couple of weeks probably didn’t change a lot over the last couple of months, but that will always be different for each person 
1 Like
For clarification, the “keep number of backups” had the same issue right? i.e. it would keep at least one backup but didn’t care about individual files? Or no?
Yup, exactly the same issue just only with files that only existed before X backup runs
1 Like
Ah, so if I set 7D:U,4W:1W,12M:1M,U:1Y then even though I’ve said I want at least 1 backup per year forever, if that 1 backup that is kept happened to have been made AFTER a particular file was deleted from the source then that file will effectively have been removed from the backup as well.
Oh - and we should probably update the Custom backup retention description to include an example usage of U. The discussions above include talk of “keep count” features like U:30 means keep at least 30 versions forever but it’s unclear whether that as included in 2.0.2.20 or just U:1Y (one annual backup forever) is supported.
We forgot to update the description before merging the U update into master after I mentioned it on the PR
1 Like