Hey tech gurus and digital superheroes! ![]()
![]()
So, picture this: I’m knee-deep in disaster recovery mode, battling a custom NAS meltdown with a dodgy HDD. The hero in shining armor? The new Synology 423+! ![]()
Now, the plot twist: my “Recreating database” quest has been on an epic week-long journey. On Jan 12th (2 days ago), it hit a snag at 62%, and since then, it’s been radio silent - no new logs, no progress, nada. ![]()
The dilemma? Do I wait for the digital deities to work their magic or hit the cancel button for a reboot? ![]()
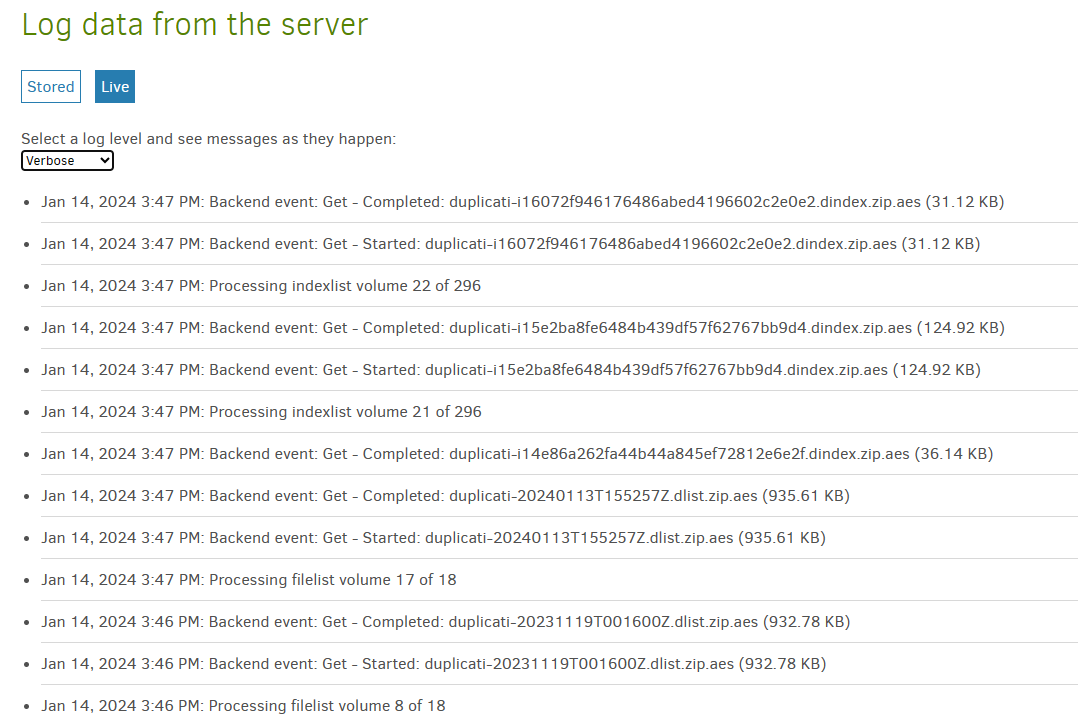
Here’s the lowdown: both instances are rocking Duplicati in docker, dancing with B2 for storing my precious 2.5 TB of data (B2 says so!). Backups have been the bi-weekly ritual for the past three years. The Duplicati maestro on the new Synology is flexing version 2.0.7.1_beta_2023-05-25.
Settings, you ask? Hold your breath:
- asynchronous-concurrent-upload-limit: 10
- concurrency-max-threads: 0
- number-of-retries: 15
Let’s peek behind the digital curtain with a snapshot of my system’s secret sauce:
lastEventId : 5951
lastDataUpdateId : 18
lastNotificationUpdateId : 0
estimatedPauseEnd : 0001-01-01T00:00:00
activeTask : {"Item1":6,"Item2":"e4f93b91-db68-44f2-9b0d-08f55f62cb6b"}
programState : Running
lastErrorMessage :
connectionState : connected
xsfrerror : false
connectionAttemptTimer : 0
failedConnectionAttempts : 0
lastPgEvent : {"BackupID":"e4f93b91-db68-44f2-9b0d-08f55f62cb6b","TaskID":6,"BackendAction":"Get","BackendPath":"duplicati-id6bcf7315f654aeb9c073ca4cfc4b1f0.dindex.zip.aes","BackendFileSize":37533,"BackendFileProgress":0,"BackendSpeed":-1,"BackendIsBlocking":false,"CurrentFilename":null,"CurrentFilesize":0,"CurrentFileoffset":0,"CurrentFilecomplete":false,"Phase":"Recreate_Running","OverallProgress":0.620590448,"ProcessedFileCount":0,"ProcessedFileSize":0,"TotalFileCount":0,"TotalFileSize":0,"StillCounting":false}
updaterState : Waiting
updatedVersion :
updateReady : false
updateDownloadProgress : 0
proposedSchedule : []
schedulerQueueIds : []
pauseTimeRemain : 0
And for the grand finale, the last 4 Logs (Profiling):
12 sty 2024 16:34: ExecuteScalarInt64: SELECT "ID" FROM "Remotevolume" WHERE "Name" = "duplicati-id6bc321cb3d4419a8beddf3c303bf812.dindex.zip.aes" took 0:00:00:00.000
12 sty 2024 16:34: Starting - ExecuteScalarInt64: SELECT "ID" FROM "Remotevolume" WHERE "Name" = "duplicati-id6bc321cb3d4419a8beddf3c303bf812.dindex.zip.aes"
12 sty 2024 16:34: ExecuteScalarInt64: SELECT "VolumeID" FROM "Block" WHERE "Hash" = "b2I6TJdW/8pEsjYv7TpvQxJwu9tETUs8I7vy4fc/Wnk=" AND "Size" = 102400 took 0:00:00:00.000
12 sty 2024 16:34: Starting - ExecuteScalarInt64: SELECT "VolumeID" FROM "Block" WHERE "Hash" = "b2I6TJdW/8pEsjYv7TpvQxJwu9tETUs8I7vy4fc/Wnk=" AND "Size" = 102400
So, dear tech savants, wizards, and coding sorcerers, I beckon thee! Should I hold out for the digital dawn or slam the cancel button for a fresh start? Your insights could be the magic spell my NAS desperately needs! ![]()
![]()
Drop your thoughts, hacks, or mystical incantations below. Let’s banish this tech turmoil together! ![]()
![]() #TechRescue #DigitalSOS #NASNightmare
#TechRescue #DigitalSOS #NASNightmare