Welcome to the forum @Blinky90
It’s a complex question, inherently. First, let me see if I can answer things the way you’ve asked them.
When the next backup runs, it checks for changes several ways, but modification time is a main driver.
You’d have to define corrupted as opposed to inconsistent. If, for example, you had a 1 GB file, and you modified the start and the end in the middle of file being backed up, backup sees only the change at end.
With an ordinary file, the end change would get picked up by the file modification time, and file open that triggers would cause the whole file to be scanned next backup. Meanwhile, you have a backup that’s not crash-consistent, meaning what you would have stored if the system crashed at some particular instant.
If crash-consistent matters, you use snapshot-policy. What OS is this? This only works on Windows and Linux, but Linux is rarely set up for this. Windows can also take you to the next level, which is application consistent, meaning the application knew how to flush data in a way that it will be happy with it’s restored. That has to be built into the application, otherwise the best VSS can get is crash consistent. Applications such as databases that have large files with constant changes (and maybe no modification time change) usually tell you directions on how to get an unchanging backup copy that any backup program can handle.
The same sort of result. It’s like missing a bus. If you miss the scan-for-changed files for a backup, you’ll get picked up next backup. Depending on your move, you might back up a file twice or zero times. Twice doesn’t hurt much because it’s deduplicated so no additional file data uploads are needed. The snapshot approach can help if this bothers you, but even a snapshot can pick up a file that’s halfway done its copy.
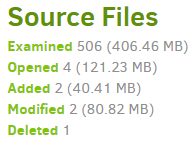
Above is the intent. There might be implementation bugs, so if you hit anything odd result, please report it
If you look at your job log, you can see how your entire defined source area is examined, some files look changed enough that they are opened for a complete check, then their new modifications are backed up: