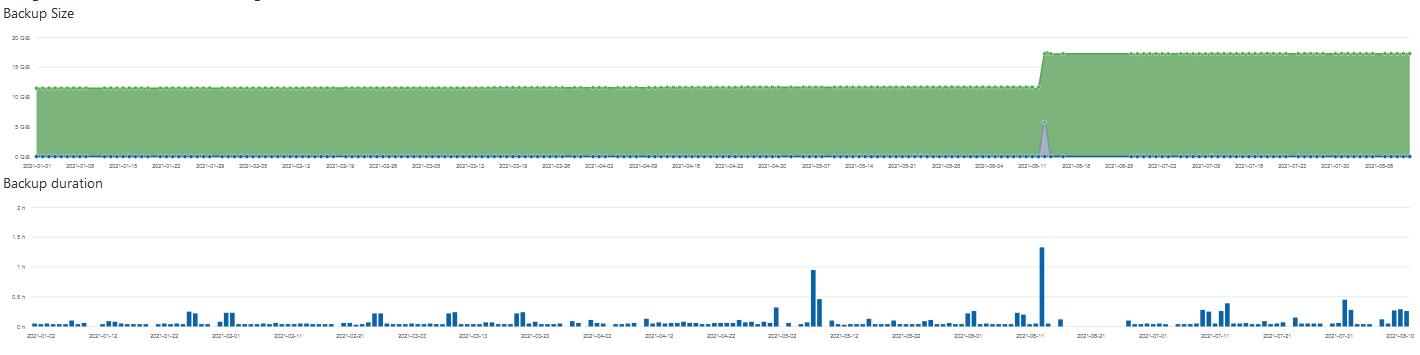
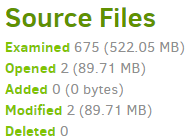
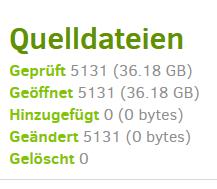
Recently I observed that one of my jobs took more than 25 mins where it used to take ony less than 2 mins before. There were no major changes/additions/deletions in the source.
Example for good run (Feb 24, duration 1,75 mins):
“DeletedFiles”: 0,
“DeletedFolders”: 0,
“ModifiedFiles”: 2,
“ExaminedFiles”: 5082,
“OpenedFiles”: 4,
“AddedFiles”: 2,
“SizeOfModifiedFiles”: 109420,
“SizeOfAddedFiles”: 508534,
“SizeOfExaminedFiles”: 38153360714,
“SizeOfOpenedFiles”: 617954,
“NotProcessedFiles”: 0,
“AddedFolders”: 0,
“TooLargeFiles”: 0,
“FilesWithError”: 0,
“ModifiedFolders”: 0,
“ModifiedSymlinks”: 0,
“AddedSymlinks”: 0,
“DeletedSymlinks”: 0,
“PartialBackup”: false,
Example for bad run (Feb 25, duration 26 mins):
“DeletedFiles”: 0,
“DeletedFolders”: 0,
“ModifiedFiles”: 5082,
“ExaminedFiles”: 5084,
“OpenedFiles”: 5084,
“AddedFiles”: 2,
“SizeOfModifiedFiles”: 38912,
“SizeOfAddedFiles”: 1494286,
“SizeOfExaminedFiles”: 38154855000,
“SizeOfOpenedFiles”: 38154855000,
“NotProcessedFiles”: 0,
“AddedFolders”: 0,
“TooLargeFiles”: 0,
“FilesWithError”: 0,
“ModifiedFolders”: 0,
“ModifiedSymlinks”: 0,
“AddedSymlinks”: 0,
“DeletedSymlinks”: 0,
“PartialBackup”: false,
bad run right after previous (Feb 26, duration 39 mins):
“DeletedFiles”: 0,
“DeletedFolders”: 0,
“ModifiedFiles”: 5084,
“ExaminedFiles”: 5087,
“OpenedFiles”: 5087,
“AddedFiles”: 3,
“SizeOfModifiedFiles”: 227174,
“SizeOfAddedFiles”: 1384393,
“SizeOfExaminedFiles”: 38156243365,
“SizeOfOpenedFiles”: 38156243365,
“NotProcessedFiles”: 0,
“AddedFolders”: 0,
“TooLargeFiles”: 0,
“FilesWithError”: 0,
“ModifiedFolders”: 0,
“ModifiedSymlinks”: 0,
“AddedSymlinks”: 0,
“DeletedSymlinks”: 0,
“PartialBackup”: false,
Why were all these files opened while there was nothing to upload?
Using Duplicati 2.0.5.1_beta_2020-01-18, target location is webdav.magentacloud.de
Appreciate any insights.