My apologies if this is answered someplace else, but I wasn’t able to find anything quite like this (though it feels basic )
I’m attempting to run a backup on about 3TB of data to an S3 (not AWS) bucket. It’s a good number of files (150M or something like it) so I expect it might take a long time to complete, but the problem I’m seeing is that the it’s taking a long time while hardly using any system resources.
The setup:
Duplicati installed as a service on an Ubuntu 20.04 VM
8 Intel Xeon cores
4GB of RAM
25GB local VM disk space (the disk image is stored on a local all flash hardware RAID6 array. Real world test transfers are pretty well steady at ~500MB/s)
1G network connection to all network shares, including the S3 bucket
Files are connected to the VM through an NFS share with a Truenas device (which routinely provides >80MB/s file transfer speeds to the VM)
Other backup software running on the Truenas sees a steady >20MB/s transfer rate when backing up
Duplicati settings I’ve change to possibly improve the upload speeds;
asynchronous-upload-limit: 0
blocksize: 500KB
concurrency-block-hashers: 8
concurrency-compressors: 8
dblock-size: 100MB
no-encryption: true (I trust the endpoint and the pipe, but plan to add encryption if I can fix the performance issues)
thread-priority: highest
What I’ve observed:
CPU Utilization: Rarely goes above 30% and never about 50%
RAM: after a couple of days the VM hits about 50% but never goes above that
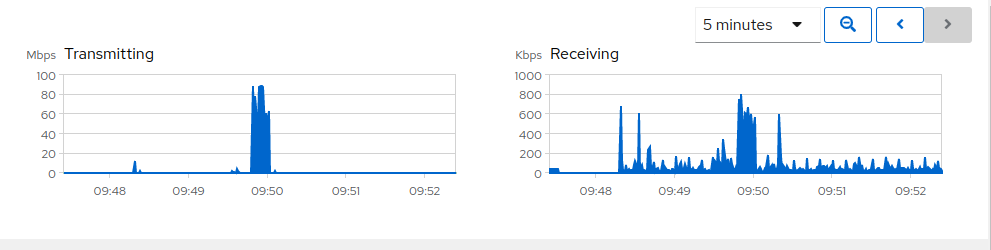
Disk usage: paltry… the indicator is near idle pretty much all the time with occasional spikes up to about 40MB/s before crashing to idle again
Network activity sits around 20M, while occasionally bobbing up to ~50M (Again, I’ve clocked the slowest connection in the chain at a steady 160M network connection)
Merely counting all the files takes literally days, followed by a steady 1.5MB/s transfer rate after that
Duplicati has the perfect feature set for what I want to do with it, but if even checking for changes takes more than a day, the performance is unworkable for a nightly backup. This is a VM doing nothing but backups and running in a test environment. I’m willing to make it bleed.
What can I do to convince Duplicati to push the ‘hardware’?
Just a guess but I’d image the source files are not local enough for Duplicati to be able to “work with them” in a proper fashion. I don’t know all the details as to why but Duplicati really wants it’s source files to be local, truly local. I like the idea but I don’t think you’ll be able to use Duplicati in this way reliably.
Have you looked at just running Duplicati directly on your NAS?
I have a setup backing up a NAS from a PC running Win 10 and performance seems all right. Snapshots are of course impossible but generally backups don’t take forever. It’s a very different configuration than the OP’s though, all is done with Windows CIFS. NFS is another thing entirely and it’s possible that the library used by Duplicati don’t work well in this case. From a quick Internet search, NFS is prone to slow file listing in some contexts, especially when not having huge amounts of RAM.
Technically there’s more than counting, processing runs in parallel, and it’s hard to isolate a bottleneck.
Channel Pipeline says what goes on inside . About → Show → Log → Live → Verbose shows file work, however for easier large scale use (and timing to the second), it’s worth setting up a log-file maybe with log-file-log-level=verbose to see if time per file times 150 million is ballpark reasonable for waiting days.
I have to say I worry about checking that many files over NFS which Duplicati obtains access to via OS. snapshot-policy is probably the fastest way to identify changed files, but it requires LVM to be available, and TrueNAS may or may not be willing. But even without that, I’d think a local file scan would be faster.
Interesting that NFS might not play nice with Duplicati. I can say that sftp gives similar performance. I could easily share the same files over smb/cifs and see if there’s a difference.
I wonder what would cause it? I don’t think RAM is the issue here, since the VM never consumes more than 50%.
Interesting… I found that the Duplicati process was niced to 19, which seems pretty low considering I set the preferences in Duplicati to give it the highest thread priority. I suspect that option isn’t actually doing anything.
I manually reniced the root Duplicati process down to -20 and now I’m seeing >15MB/s transfer rates during transfer, and the processor utilization is refularly jumping up to 70% or higher. Processing seems to be at least part of the bottleneck. No idea if the gains will continue throughout the entire backup.
I vaguely recall having seen on Windows that some of the priority stuff only applies during the operation. This might be worth a close look on Linux, for both the initial (idle) nice value, and how backup moves it.
that there is no error checking (contrary to the Windows and MacOS parts of code doing the same thing), so if something goes wrong in setting the priority nothing at all will be reported. Also ionice is not the same as renice. So if the process is processor bound, it will remains so it seems.
I’m not a C# dev and haven’t looked hard at cited code, but I’d guess that’s use-background-io-priority. thread-priority might be in code that handles System.Threading.Thread.CurrentThread.Priority
Setting low priority helps to run server process truly in background and provides CPU cycles to Duplicati only if no other process requires them.
Apparently the devs thought this was a better setting. I’m not sure, but it’s certainly not in line with
which might be out of ordinary usage, or at least amusingly extremely stated in the other direction.
The question still exists whether this plan sticks or is changed by other options for the actual work.
What I actually had in mind was someone looking at nice values at idle versus during the backup.
EDIT:
Preferably look at the thread level. Figuring out which threads are relevant might be difficult though.
Yes, doing things with VM has a side-effect that is often underappreciated, being that the host OS don’t know anything about the guest OS priorities and schedule - or not - the whole VM as a single process.
Edit: I should of course have written ‘generic host OS’. Dedicated hypervisors (such as Vmware) exist for a reason.
Update:
I’ve transferred the files to a test server and attempted running the same backup with the same settings from there. The files are now local and the server should be well up to the task (24 threads, 64G RAM, storage is on a local ZFS array).
Results:
The counting phase still takes 3 days to complete (Yes, I know it’s doing more than just counting files ) The transfer rate after several days is ~580KB/s (even though I’ve confirmed that the target can easily handle 15MB/s). RAM usage, processing, and other resource usage appear to be minimal.
If the storage is local, iops and bandwidth shouldn’t be a problem. Duplicati should be packaging up files and sending them to storage at something like the max transfer rate. I know the files are small and already compressed, but I’d guess that would put the processing as the limit, but the CPU is seeing ~2% utilization.
Any suggestions of any additional troubleshooting I can do to find out where things are going wrong?
Another update:
I installed cockpit so I could monitor the data transfer. Network traffic is pretty well zero, with occasional 100Mbps squirts of data to the S3 share.
I’m at a total loss as to what the issue could be. It’s a lot of files, but I’m kinda shocked that Duplicati would fall all to pieces like this over a 3T backup.
I haven’t tried that yet. I assumed that moving to a local file system from NFS would make it irrelevant. I’ll give it a try though.
At this point, I’m more worried about the 700KB/s transfer rate, which seems really low. No matter how many files there are, with the local file system I would think that, after it’s done with the counting phase, it should be able to package the files quickly and send them up in 100MB chunks or stress some system resource (disk io, processor, RAM, etc). Though it’s possible I’m misunderstanding how Duplicati works.
from what your monitoring tool describes, it seems to be what happens (except for the ‘quickly’ part).
While it’s wild speculation, maybe the Duplicati zip library is single threaded ? Maybe take a look with htop to check on that ?
In this case if your files are already compressed, it’s often a worse case for compression and if a single core is used, it could be rather slow. It may not apply though, since there is a file (default_compressed_extensions.txt) setting the file extensions that should not be compressed again (unless all your files are compressed and have an unusual extension or none)
Hmmm… I can say it’s definitely using multiple threads, though it takes some serious priority adjustment to get it much above 50% utilization of all cores.
The point about already compressed files is interesting, though. The data is from an MRI machine. So, it’s almost entirely images (compressed with JPEG2000 or LZW, I think), but there would be no hint of this from the extensions.
Maybe I could see if I can turn off compression entirely and see if the speed improves…
There’s not really a counting phase. It’s pipelined as described. Is this initial backup or an update?
Update is probably dominated by searching for changes among 150 million files. Initial is probably dominated by packaging and uploading all the easy-to-find new data. This is parallelized per your:
and it’s not clear writing randomly to 8 dblock-files-to-be will speed things up. Hardware dependent.
Do you have any measurements of things like disk utilization (maybe. from %util in sar) or iowait?
“Quickly” may depend on the random-writes speed of the tempdir folder. Is this now on hard drives?
Regardless, you should be able to see the files grow. Note that if source files are smaller than value
then you get one block of the file size (plus attribute metadata). Eventually it hits 100 MB and is sent.
is I think increasing the random-reads parallelism of the source side. Is this good with your hardware?
If the ZFS array is mechanical, it’s probably easy for it to be slower at multiple random read/write than network uplink can move data, and there are limited ways to avoid this. Maybe a RAM disk might help because you definitely don’t look CPU limited, but were there some stats on how utilized the array is?
The OS probably has some ability to make up for this, but there’s a bottleneck somewhere to discover.
IMO it depends on the storage. My PC mechanical drive does 4KB random reads and writes at 1 MB/s.
If you happen to have an all-flash array, then ignore much of the above. If not, probably need metrics…
I guess I’ll also mention that the database can grow and get slow at over a million or so blocks tracked, meaning your blocksize is too low, however if you’re on initial backup (are you?) it might not slow yet, because you might see this as high CPU usage (not happening) and maybe high disk use (not known).