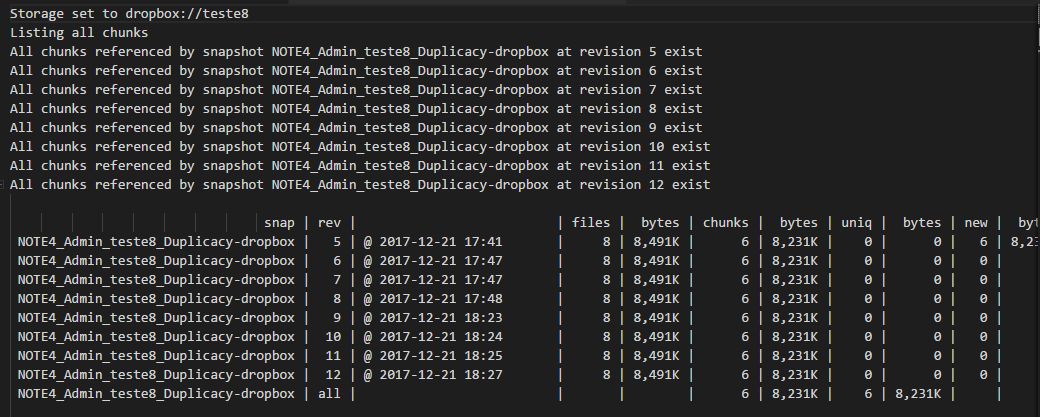
I finally got the results together for the second test - larger set of big files.
Source included 5 files of total size a bit over 15Gb. Some files were compressible, so that default zip compression would end up with approx. 10Gb archive.
So far I rested backup timing only. I plan to check restore speed as well (when I have time).
Results are not bad, but still a bit disappointing. Full details also available in the Google spreadsheet I shared earlier, but below you can find all the numbers as well.
| Backup | Time | Destination | Parameters | |||
|---|---|---|---|---|---|---|
| Run 1 | Run 2 | Run 3 | Size | Files | Folders | Duplicati 2.0.2.6 |
| 1:12:40 | 1:17:38 | 1:11:14 | 10,968,733,985 | 421 | 1 | Deafault compression |
| 0:44:34 | 0:41:00 | 0:41:38 | 11,153,579,823 | 427 | 1 | –zip-compression-level=1 |
| 0:56:30 | 0:51:12 | 0:49:18 | 15,801,175,593 | 605 | 1 | –zip-compression-level=0 |
| 0:31:01 | 0:30:44 | 0:29:58 | 15,800,984,736 | 605 | 1 | –zip-compression-level=0 |
| –no-encryption=“true” | ||||||
| Duplicacy 2.0.9 | ||||||
| 0:27:27 | 0:27:23 | 0:27:24 | 10,931,372,608 | 2732 | 2931 | -threads 1 |
Details on the source:
| Size | File name |
|---|---|
| 5,653,628,928 | en_windows_server_2016_x64_dvd_9327751.iso |
| 1,572,864,000 | DVD5.part1.rar |
| 1,572,864,000 | DVD9.part1.rar |
| 5,082,054,656 | disk1.vmdk |
| 1,930,806,927 | dotnetapp.exe.1788.dmp |
Compressability
| Size | Compression |
|---|---|
| 10,788,967,173 | InfoZip default |
| 10,968,733,985 | Default compression |
| 10,931,372,608 | Duplicacy |
| 11,153,579,823 | –zip-compression-level=1 |
| 15,801,175,593 | –zip-compression-level=0 |
| 15,812,218,511 | Source |
The results are not too bad, but still a bit disappointing - CY is able to maintain same or better compression/deduplication as the TI defaults but showing noticeable performance difference.
Although TI can get closer to those times in expense of space efficiency,
I will also have to note, that CY can perform even better with multithreaded upload.