How can I do a backup dry-run seeing the details of the differences between source and destination (create/modified/deleted and the full path)?
E.G.
I run a full backup, single version
I delete a single file locally
What command can I run to get the path of the deleted file locally that will be deleted if I run the backup in the destination?
The COMPARE command seems to work only between completed backups and not between local state and new backup
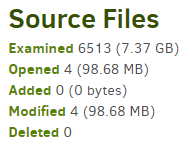
If I run a BACKUP command with dry-run enables, it only gives me a summary of what’s chagnes (number of added/deleted/modified) and setting the log level to verbose does not seem to highlight any deleted file.
In terms of your example, note that deleted source files aren’t deleted from old backup versions, but aren’t present in the current backup. If the concern is what vanished, backup, compare, tweak source or backup.
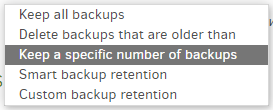
If the backup looks seriously unwanted, you can run the delete command to delete it before some retention option you chose (especially if using backup thinning, either smart or custom) decides it’s the time to keep.
thanks for the reply; the LocalListChangesDatabase looks promising; do you know how I could use that as one of the two databases for the comparison (possibly without altering the source code myself)?
I only have one backup version, my only concern is to know what will be deleted from the remote backup (so what’s effectively been deleted locally after the last backup).
As a workaround, I could probably increase my backup version to keep to 2, run the backup and then compare the two versions, but:
I was hoping there was a simpler, more native way
I do not appreciate the impact of increasing the DB versions to keep to 2; will that only store the delta or will it use the full size of 2 backups? if activated after like in my case, will it only add the new version or will it require a re-backup of everything?
That’s not a database. It’s a source file that digs through job database (I think – see if you agree).
The job database holds information about the backups that it has done, so lacks future forecasts.
Incremental backups
Duplicati performs a full backup initially. Afterwards, Duplicati updates the initial backup by adding the changed data only. That means, if only tiny parts of a huge file have changed, only those tiny parts are added to the backup. This saves time and space and the backup size usually grows slowly.
Unless you are extremely tight on storage space, or have cloud storage that would penalize you for test, easiest plan is to check space use, try 2, run a backup, check space use. You might decide 2 is too few, however if storage jumps, drop it down to 1 so wasted space will be removed by the automatic compact.
Make sense; just looking at names I thought it was an interface implementation of a ghost destination that was in reality the local directory. I was completely off track.
Alas, it does not seem to mention adding a second version later on and consequences; I can probably create a new test backup with dummy data and try to see what happens.
My storage is in Azure, so it’s pay-per-gb; given the backup is 2TB, if it doubles it, it becomes way more expensive; I presume I will need to run tests to figure this out, too.
Quoting it on the second and all subsequent versions:
Afterwards, Duplicati updates the initial backup by adding the changed data only. That means, if only tiny parts of a huge file have changed, only those tiny parts are added to the backup. This saves time and space and the backup size usually grows slowly.
It won’t unless you have an odd case where you change each file rather thoroughly. Only changes upload.
To see your level of change, look at your job log, which in large print summarizes changes at the file level.
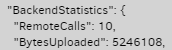
In the more obscure Complete log, it shows you what you uploaded. Space use can’t grow more than that however it can grow less than that because as old versions get deleted, old irrelevant data can be deleted:
If it doubles, revert to one. I’m not an Azure pricing expert, but only Archive has 180 day minimum, right?
And (unlike another vendor, you’re not charged for peak use, are you? Deleting early stops the charging. Understand the full billing model for Azure Blob Storage
For data and metadata stored for less than a month, you can estimate the impact on your monthly bill by calculating the cost of each GB per day.
Please do. If you happen to have some spare local drive space, the storage behavior should be identical.
You won’t have to worry about whether my read on Azure pricing is correct. You can also read it yourself.
What I meant is creating a backup with 1 version, then modifying the settings to 2 and then running. That piece of docs may just refer to setting it to 2+ on the first instance. I just hope it works the same way.
Archive cost near to nothing per TB, but if the data is pretty dynamic and you archive, then destroy to make space to a new backup, is not suitable.
It doesn’t. The retention setting doesn’t come into play until after backup.
The status bar says “Deleting unwanted files …”. You can see that now.
It’s pretty quick unless it does the occasional compact that takes longer.
If things varied by number of backups kept, what about the other cases?
Ignoring the complicated ones, the simple age based could find 1 or 100.
I was hoping to hear whether you use Archive. If not, less to worry about.
If you use Archive, Duplicati backups (as explained) don’t churn like that.
The exception would be if your source data churns. Look at the log stats.
“DeletedFileSize” is the one for that. You get it now, mostly by compacts.
Those clean up wasted space. This wasted space is from source churn.
If source never changed and was kept forever, there’d be no delete need.