I have been a long time Duplicati user, and have four backup jobs directing backups to various destinations (two local HDDs and two remote over SFTP/SSH). Over the years there have been times when Duplicati would suffer database corruption and I would rebuild (when files are local) or wipe it out and start over (when files are remote). So I’m used to keeping an eye on Duplicati and wiping its bottom when it needs help.
I upgraded to 2.3.0.1 as soon as it came out a few days ago, and have noticed a significant change in behaviour since doing so.
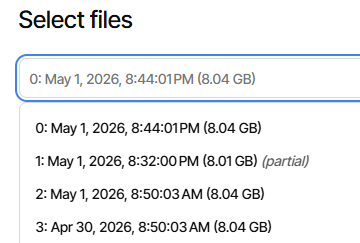
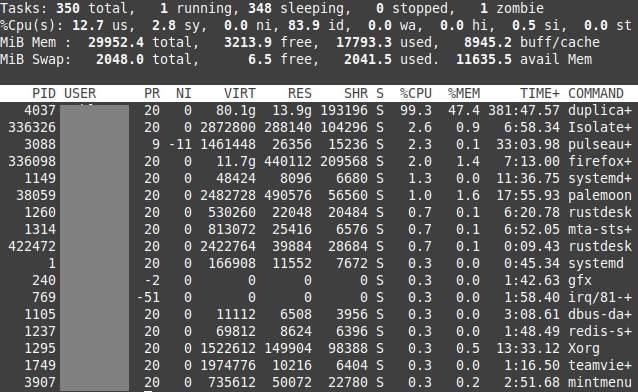
One of my jobs appears to be stuck on “Completing previous backup …”. The live log shows no new activity, so I have no idea what it is doing. The CPU usage is at 100%, all being gobbled up by the Duplicati task. I have restarted a couple of times and each time this job restarts it goes straight to “Completing previous backup …” and stays there.
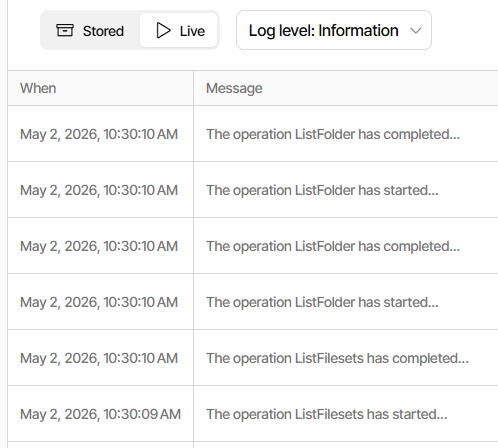
The last few log entries (Information level) that are in the log are as follows:
ExecuteScalarInt64Async:INSERT INTO "Fileset" ("OperationID","Timestamp","VolumeID","IsFullBackup")VALUES (66,1776348063,4682,0);SELECT last_insert_rowid();took 0:00:00:00.000
Starting - CommitTransaction: Unnamed commit
CommitTransaction: Unnamed commit took 0:00:00:00.000
That last one was over an hour ago, nothing since.
Could be a bug?
What do you suggest I do? Wipe this job and start again? Roll back to previous version?