As I said:
Maybe the developer can at a minimum update the new documentation that was created.
Old manual had more detail, including the warning below, but documentation isn’t a great replacement for protective code. Strangely, I can’t find any GitHub issues just on this.
When the dust settles in the discussion here, maybe someone should file one, since discussion in forum is easy to lose track of, whereas issues get tracked more formally.
Creating a new backup job is in the older long version of the manual. New one lacks it.

Yes and no, IMO. I’m not the dev, and there’s probably some early development history.
Command Line Interface CLI came before the server and GUI, and it is still in use today.
Each command also requires the option
--dbpath=<path to local database>, but if this is not supplied, Duplicati will use a shared JSON file in the settings folder to keep track of which database belongs to each backup. Since there is no state given, the remote url is used as a key, because it is expected to uniquely identify each backup. If no entry is found, a new entry will be created and subsequent operations will use that database.
By intent, command line runs can run independently of each other and of what GUI does (however if you want to run a GUI job from command line, use ServerUtil to request that, which also keeps your CLI run of Export As Command-line from colliding with a GUI run).
Back to databases, the model above associates a destination folder (given in URL form) with database assignment, so if one happened to put different source trees into a single destination with different Duplicati.CommandLine.exe (Windows name) runs, database is experiencing whiplash in terms of what each version asks, but keeps destination straight.
You can cause the same change-of-mind in the GUI too, and it’s fine. Each version keeps what Source it’s told, and one folder of Destination files has data from the varying Source.
Different (intentionally or not) Source through one job database to one Destination works.
What doesn’t work is multiple job databases thinking they are the DB for same destination because (right at the initial backup for new job) the new job will see files it’s not expecting. Pushing through that might work, but the new job will then lay surprises for the original job, probably including some extra files, and (I think) potentially some missing ones from doing compact or something which will delete files that the original job had put on the destination.
So returning to the question, one piece at a time:
The job database keeps track of Source files, and the Destination files from processing.
The “it” here is a bit vague, and I’ll dig in because you have the experience to follow this.
CommandLine does have the map of destination URLs to databases in dbconfig.json, and in a sense that’s “its backups” although it doesn’t know which have fallen into disuse, and (I think) making it forget a mapping is kind of a hand-edit of a text file, so not elegant.
GUI has server database Duplicati-server.sqlite and a definite idea of “its backups”. Destination is expressed in URL form, and it could and should question destination reuse.
I’ll now do a test with a recent Canary public-testing build to make sure it still doesn’t look.
I exported a job and imported it to create a new one in same Duplicati. Try to save it, see:
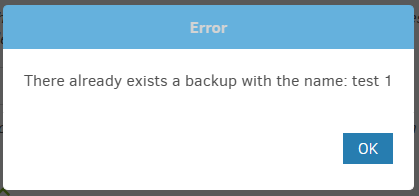
Fix the name, and it saves with no complaint, so now I have two jobs with two databases. Import doesn’t import the old database path, which is probably a good idea), but sets the situation where two jobs with two databases think they both own one destination, so bad.
One could try to catch the error based on destination URL, but a given destination could support multiple protocols, such as FTP/FTPS, and SSH/SFTP, and WebDAV, and SMB.
One could have the Destination Test connection button look more closely for files that might be Duplicati files, but false positives could occur, and Duplicati supports option for:
--prefix (String): Remote filename prefix
A string used to prefix the filenames of the remote volumes, can be used to store multiple backups in the same remote folder. The prefix cannot contain a hyphen (-), but can contain all other characters
allowed by the remote storage.
* default value: duplicati
which handles what I view as a rare case (but I think it’s been used). This unknown is in Advanced options, so is hard to handle as early as Destination, but it could sort of try.
Another potential unwanted end is picking some folder full of other existing files. Duplicati only looks at its own files, but the user might not want backups polluting, say, Documents.
At job Save time, additional checks happen in both JavaScript and run by Duplicati server. Server could look at the final combination of URL and prefix and flag any seeming conflict, however it would still be fooled if a destination used different accesses in the different jobs.
It also could get a surprise at actual backup time because it has not seen destination files which might have been put there by a Duplicati on another computer. No global tracking…
For a local check based on database information, it would seem nearly as good to check whether a previous backup had been configured to that destination folder, though I gave ways where that could fail. Actually looking is safer, but a look at Save time may surprise.
Destination access at other times (e.g. Backup) should be no surprise, and it’s done right away at start of backup, and destination use is prevented by failing backup with a popup.
Popup error has accidental corruption in mind, and says to Repair, which might be wrong.
A backup is some dlist (file list and reassembly info), dblock (data), and dindex files. When things go perfectly, everything aligns as expected. If not (interruptions can do this), there may be missing or extra files perceived. An extra file happening this way looks much like an extra file produced by any other backup run by this or some other Duplicati server.
They are properly identified in the job database, but that’s per-job not per-Duplicati server. Possibly some of this is historical to when the CLI database was per-destination, which is ideally treated like a job with some consistency, e.g. of the source files that it’s backing up.
So first question is on ways to avoid misconfiguration, and then second is how to limit the damage when it happens anyway. One way to kill a backup was to restore a stale job DB from some other backup (maybe a drive image), try to backup, and get told to do Repair which will try to reconcile Destination to stale DB-of-record. I think that will be stopped by.
So that one does a sanity check on backup version times I think (I’m not a C# developer).
If Backup funnels users into Repair when re-use is attempted, a similar time check could realize that mostRecentLocal doesn’t exist, yet after prefix filtering, Destination has some.
This scenario is fine if one is using GUI Database Recreate (delete and repair), repair has this two-way behavior I’m not sure I like where it either tweaks things or does DB recreate:
`Usage: Duplicati.CommandLine.exe repair []
Tries to repair the backup. If no local db is found or the db is empty, the db is re-created with data from the storage. If the db is in place but the remote storage is corrupt, the remote storage gets repaired with local data (if available).`
I think the help text supports my thinking that it has corruption in mind, not config dangers. Regardless, making Repair more sensitive to other situations may be an approach to this.
I’m thinking that there was a recent idea of having the DB get recreated automatically if destination exists but DB doesn’t (maybe as a convenience), but I can’t find that currently.
Regardless, the dev might know unless I imagined it, and I’ve given enough talk already, and I’m not the person knows the code or history. We’ll see if the dev will give comments.
The web UI in 2.1 is a bit flaky for me, but I’m not seeing this, if I understand correctly.
There’s not AFAIK a show of the job name after the restore. It does show in progress.

and afterwards there’s a sometimes-optimistic success message in main screen area.
Status bar returns to idle state, giving the schedule status for next job, or saying none.
Problem needs more information, but so far I can’t repro any kind of wrong-name bug.
Maybe the dev will recognize it, but more important I think is comment on damage by configuring two jobs to one destination, then maybe running Repair when told to do it.
suggests that the dev was receptive to the idea, but then lost track of intent for a check. Previous work was spare-time. Now it’s paid, by Duplicati, Inc. Planning is more formal.
Anyway, it’s on the table again. Don’t need to use my ideas, but something needs work. Preferably this won’t get to design-by-committee, but you might also have design ideas, keeping in mind the existing design, as I’ve tried to describe it in quite some detail here.
For your restore issue clarification, I’d suggest a new topic, leaving this for original topic.
Knowing that most went well when not falling into a bad-config-that’s-too-easy was nice.
EDIT 1:
Add option to automatically create database if none exists #5932 is what I tried to recall, which maybe means if that gets added and chosen, the second job on same destination builds a second database for the same destination, instead of a popup error on problem. Similar problem to manual configuration of two jobs into same destination results though.