In the meantime, you can get DB Browser for SQLite (a.k.a. sqlitebrowser) to look around.
Database can be opened read-only, and for even more safety, browse on a copy, not original.
Simple analysis is pretty easy. For example you can find largest known file with a single click.
Sometimes sparse files can blow things up. You could also use du or find on Source area.
Finding the size of a given backup version is a little more, but not awful. An example of SQL:
SELECT sum("Blockset"."Length")
FROM "FilesetEntry"
JOIN "File" ON "File"."ID" = "FilesetEntry"."FileID"
JOIN "Blockset" ON "Blockset"."ID" = "File"."BlocksetID"
WHERE "FilesetEntry"."FilesetID" = 562
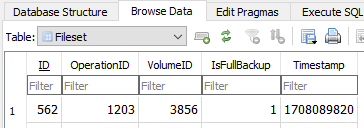
The 562 is an ID from my Fileset table. Yours will be different. Timestamp is UNIX epoch time.
EDIT:
I’m wishing that The FIND command could give a total in addition to its individual file sizes.
Still, one can find big files by using it and looking for some string like " GB)" in the output.