In Advanced options under Options, see if setting and checking this helps. It’s later in options dropdown in a separate section titled Zip compression:

Before we go on, I’d like to pause and pose a question: Is the value we get from conducting this effort worth the time? If this effort is going to help Duplicati get better, then I’m definitely happy to continue to help. But, as a user with a bunch of media files backed up using this job, I’m starting to wonder if it would be better to nuke these backups and start again with a more appropriate block size. These media files are all ripped by hand from physical media that is still in my possession, so while I’m not eager to re-do everything, I can certainly replace an accidentally deleted album or show season should the occasion arise.
Obviously going that route means we won’t be able to figure out what the problem is, and I DO want to help if I can.
Please let me know what you think!
I have to admit that I’m always curious to understand why stuff does not work. Sometimes it exhumes something really interesting because it’s a generic bug that has not been understood before, sometimes it’s a useless defect that can’t be found anywhere else, sometimes it’s impossible to find what happened and it’s a bit frustrating yes to have wasted time.
That’s good enough for me! I’ve set the zip-compression-zip64 setting, and I’m running the bug report again.
The Bug Report finished, but the browser is taking a long time to give me the file. Is it saved somewhere on the host so I could just copy it out to my file system?
On my Ubuntu test system, when it is saying me that it is ready for download, it’s in the /tmp directory.
Thanks… I got the file. I’m having trouble syncing it to my Nextcloud instance. I need to troubleshoot that, but I’m not sure if I’ll get it done today. Be patient though, I’ll deliver, I promise!
Alright, give this a shot: Bug Report (2.5GB)
Hello
this is what I have found
select * from fileset;
679|1408|5937|1|1673958235
695|1439|6030|1|1676636816
720|1470|6258|1|1679315747
752|1502|6428|1|1682080527
784|1535|6614|1|1684930943
800|1551|6706|1|1686313216
802|1553|6721|1|1686485740
804|1555|6734|1|1686658500
805|1556|6741|1|1686744970
807|1562|6750|1|1686917700
this is what I did to emulate a retention handling:
delete from fileset where id in (800,802,804);
DELETE FROM "FilesetEntry" WHERE "FilesetID" NOT IN (SELECT DISTINCT "ID" FROM "Fileset");
delete from fixedfile WHERE "ID" NOT IN (SELECT DISTINCT "FileID" FROM "FilesetEntry") ;
DELETE FROM "Metadataset" WHERE "ID" NOT IN (SELECT DISTINCT "MetadataID" FROM "Fixedfile");
DELETE FROM "Blockset" WHERE "ID" NOT IN (SELECT DISTINCT "BlocksetID" FROM "Fixedfile" UNION SELECT DISTINCT "BlocksetID" FROM "Metadataset");
DELETE FROM "BlocksetEntry" WHERE "BlocksetID" NOT IN (SELECT DISTINCT "ID" FROM "Blockset");
DELETE FROM "BlocklistHash" WHERE "BlocksetID" NOT IN (SELECT DISTINCT "ID" FROM "Blockset");
And here are a few tests with my system (according to cpubenchmark, my processor is scoring 3000 passmark while yours is at 3500 if it’s a xeon e5-2407v2 like you implied in Error: The socket has been shut down - #63 by tkohhh.
I begin with the database at its primary state (as extracted),with data deleted as above.
sqlite> select count(*) from (SELECT "Hash", "Size", "VolumeID" FROM "Block" WHERE "ID" NOT IN (SELECT DISTINCT "BlockID" AS "BlockID" FROM "BlocksetEntry" UNION SELECT DISTINCT "ID" FROM "Block", "BlocklistHash" WHERE "Block"."Hash" = "BlocklistHash"."Hash"));
37
Run Time: real 185.880 user 81.729881 sys 89.865376
sqlite> select count(*) from (SELECT "Hash", "Size", "VolumeID" FROM "Block" WHERE "ID" NOT IN (SELECT DISTINCT "BlockID" AS "BlockID" FROM "BlocksetEntry" UNION ALL SELECT DISTINCT "ID" FROM "Block", "BlocklistHash" WHERE "Block"."Hash" = "BlocklistHash"."Hash"));
37
Run Time: real 29.486 user 21.750463 sys 3.445500
sqlite> select count(*) from (SELECT "Hash", "Size", "VolumeID" FROM "Block" WHERE "ID" NOT IN (SELECT "BlockID" AS "BlockID" FROM "BlocksetEntry" UNION ALL SELECT "ID" FROM "Block", "BlocklistHash" WHERE "Block"."Hash" = "BlocklistHash"."Hash"));
37
Run Time: real 179.944 user 69.144392 sys 87.384809
sqlite> select count(*) from (SELECT "Hash", "Size", "VolumeID" FROM "Block" WHERE "ID" NOT IN (SELECT "BlockID" AS "ID" FROM "BlocksetEntry" UNION ALL SELECT "ID" FROM "Block", "BlocklistHash" WHERE "Block"."Hash" = "BlocklistHash"."Hash"));
37
Run Time: real 165.787 user 69.276944 sys 88.195351
sqlite> select count(*) from (SELECT "Hash", "Size", "VolumeID" FROM "Block" WHERE "ID" NOT IN (SELECT DISTINCT "BlockID" AS "ID" FROM "BlocksetEntry" UNION ALL SELECT DISTINCT "ID" FROM "Block", "BlocklistHash" WHERE "Block"."Hash" = "BlocklistHash"."Hash"));
37
Run Time: real 24.444 user 21.569854 sys 2.658428
sqlite> pragma cache_size=-200000;
Run Time: real 0.000 user 0.000000 sys 0.000057
sqlite> select count(*) from (SELECT "Hash", "Size", "VolumeID" FROM "Block" WHERE "ID" NOT IN (SELECT DISTINCT "BlockID" AS "ID" FROM "BlocksetEntry" UNION ALL SELECT DISTINCT "ID" FROM "Block", "BlocklistHash" WHERE "Block"."Hash" = "BlocklistHash"."Hash"));
37
Run Time: real 24.499 user 21.804207 sys 2.648285
sqlite> drop index "nnc_BlocksetEntry";
Run Time: real 8.284 user 1.432280 sys 5.766403
sqlite> pragma analyze;
Run Time: real 0.000 user 0.000050 sys 0.000000
sqlite> pragma optimize;
Run Time: real 0.002 user 0.000601 sys 0.000000
sqlite> select count(*) from (SELECT "Hash", "Size", "VolumeID" FROM "Block" WHERE "ID" NOT IN (SELECT DISTINCT "BlockID" AS "ID" FROM "BlocksetEntry" UNION ALL SELECT DISTINCT "ID" FROM "Block", "BlocklistHash" WHERE "Block"."Hash" = "BlocklistHash"."Hash"));
37
Run Time: real 24.581 user 22.079502 sys 2.182641
sqlite> select count(*) from (SELECT "Hash", "Size", "VolumeID" FROM "Block" WHERE "ID" NOT IN (SELECT DISTINCT "BlockID" AS "ID" FROM "BlocksetEntry" UNION ALL SELECT DISTINCT "ID" FROM "Block", "BlocklistHash" WHERE "Block"."Hash" = "BlocklistHash"."Hash"));
37
Run Time: real 24.190 user 21.979442 sys 2.172846
sqlite> select count(*) from (SELECT "Hash", "Size", "VolumeID" FROM "Block" WHERE "ID" NOT IN (SELECT DISTINCT "BlockID" AS "ID" FROM "BlocksetEntry" UNION SELECT DISTINCT "ID" FROM "Block", "BlocklistHash" WHERE "Block"."Hash" = "BlocklistHash"."Hash"));
37
Run Time: real 35.799 user 32.849523 sys 2.872120
Even in the worst case I am in the 3 minutes ballpark.
Fun details: adding an index has a (bad) impact only because the query is using (erroneously) a simple ‘UNION’. If using UNION ALL having (and using) this index has no impact. Using DISTINCT has actually a good impact on performance.
Your system is more in the 40 minutes territory.
So it seems to have terrible performance. Not sure if it’s because you have a HDD and my system as SSD. It don’t seem enough to explain it to me.
A very common reason for bad performance with Linux systems is swap fully used.
It’s difficult to check for that if not having the backup running while connected to the computer - I don’t remember having seen an alarm logged somewhere ‘swap full !’. OTOH if you have a monitoring system it’s easy to check.
It’s a Xeon E5-2420 v2, so benchmark is 6300
I’ve never looked at swap before, but my data shows zeros across the board for that machine. By contrast, my plex machine (running Ubuntu) at least shows some data. I’m not sure if this means that swap is not being recorded correctly, or if there’s something else going on.
+--------------+---------+------------+
| swap | Server2 | plex |
+--------------+---------+------------+
| free | 0 | 2147479552 |
+--------------+---------+------------+
| in | 0 | 0 |
+--------------+---------+------------+
| out | 0 | 0 |
+--------------+---------+------------+
| total | 0 | 2147479552 |
+--------------+---------+------------+
| used | 0 | 0 |
+--------------+---------+------------+
| used_percent | 0 | 0 |
+--------------+---------+------------+
I’m going to do some testing of my own today (on my desktop) and see if I can replicate your findings. Assuming I do, this points to a problem with my setup (hardware or software) that was triggered by the Duplicati update.
It probably means that Server2 has been setup without swap. Not setting up a swap for a Linux computer is generally considered as not optimal.
Here’s a thread on swap in Unraid: https://forums.unraid.net/topic/109342-plugin-swapfile-for-691/
I’m no expert on this stuff, but wouldn’t the swap only be used when physical RAM was unavailable?
I don’t think this is a factor here, because the slowness is the execution of the query, not writing to or reading from the destination. The Duplicati database is on an SSD in my system.
yes of course however you can never be sure that at some point the physical RAM is not enough. It’s said in your linked article (when you install apps…)
In this case all is right (unless you setup the temp file on the HDD ![]() )
)
True, but I can look at my RAM usage and see what happened in the past (captured every 10 seconds). I suppose it’s possible that there’s a 10 second interval where all the RAM was used and then returned to normal before the next reading was taken, but it seems unlikely. Who knows though!
temp is also stored on the SSD.
I did have a thought that I’m going to test. The location used for storing Duplicati’s files is a FUSE. This is standard usage in Unraid for good reasons, but if you understand what’s going on, you can safely bypass the FUSE. So, I’ve updated my bind mounts in the Duplicati container for both /config and /tmp to bypass the FUSE.
The theory is that something changed in the Duplicati code that impacts how it interacts with FUSE file systems.
Who knows… I’ll report back after the job runs tomorrow.
Well look at that:
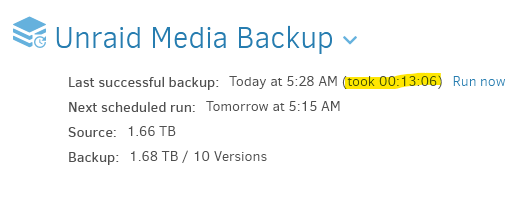
This seems to be back in line with what I was seeing before the update to 2.0.7.1.
So, I guess the question now is: what might have changed in Duplicati to change how it interacts with a FUSE?
Apologies if this was already mentioned in this thread. I tried searching but didn’t come up with anything. When you upgraded, did you upgrade Duplicati within the existing docker container somehow or did you get the latest docker container and install that on top of your existing one?
I don’t even have a theory as to what happened, but just wondering if it is not Duplicati’s behavior that has changed but something within the container itself.
Across all of my containers, I always update the tag on the container and then redeploy. This effectively wipes out the previous install and starts fresh with the new version. The /config and /tmp directories are persistent, of course.
Well, I guess that what @Lerrissirrel implied is that a Docker container is not a zip format, it’s packing some additional software that can evolves over time. AFAIK the only Docker related code changed in the official image (duplicati/duplicati) between the 2 betas was first basing on ‘latest’ mono image (mono:6) then a certificate related change. This mono:6 image is based currently on Debian 10 (buster) if I understand correctly the Docker registry. Now I don’t know much about Docker, stop me if I’m wrong but if I understand correctly, the docker image from 2 years ago was based on the state of the mono:6 image at the time, it was an older Debian 10. So if you stick to the ‘official’ image there was barely a change in the underlying software.
Then there is also the (much more popular) image from linuxservers.io based on Ubuntu (linuxservers/duplicati). It seems that these guys are updating the base image more frequently because they are not basing on the mono image, they are installing mono themselves in a vanilla OS image; so between the image in 2021 and the current image the base OS was not the same, I think in 2021 it was Bionic, now it’s Jammy. If you never touched your Duplicati install, you did a jump from Bionic to Jammy with this update (if you used the more frequently used image from linuxservers.io that is).
Yeah, thanks gpatel, I forgot to ask which docker image! Although, again, even knowing that, it only gives us direction for more experimentation/debugging.
I do indeed use the linuxserver/duplicati image. I don’t have history of when I’ve updated it, but I’ve at least updated it once or twice this year. The last time (prior to the Duplicati update that I pulled on June 1st) was maybe a month or two ago.
So, if it was something that linuxserver.io did, it was between the last time I updated a month or two ago and when they pushed the 2.0.7.1 image. I’m on their discord server, so I’ll ask if anybody knows what might have caused this.
Also, just to prove that the FUSE is in fact the issue, I’ve switched back to the FUSE for tomorrow morning’s backup. If the FUSE is the culprit, then I should see the long runtime.
It’s still a little curious that I’m having trouble on only one of my three backup jobs. However, I suppose that could be explained by the large database size of the backup in question.