To add a bit (in case you don’t have a full set of databases to move – that’s the easy way to reconnect), every “Add backup” job, whether “Configure a new backup” or “Import from a file”, will not know about a previous backup job database, so will make a new random pathname, editable in the Database screen:
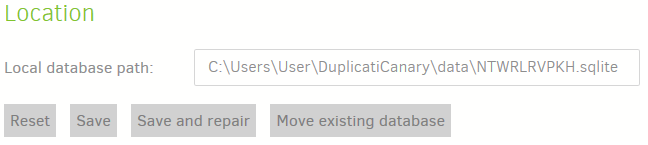
If you don’t even have the old backup job database, you can use the Recreate button to recreate it, but ideally you have the old backup job database and just want to move it in. You can either rename it onto whatever new random path was invented (there won’t be anything there until initial backup), or edit the “Local database path” field after moving the old backup job’s database in. Editing activates the buttons, including “Save”, which (assuming all the moving and changing worked) will double-check. Click “Yes”:
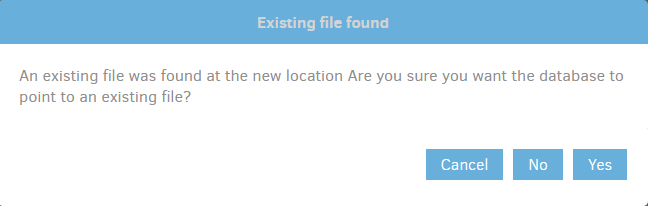
If you think this should be better documented in the manual, I’d agree. I’m not even sure there’s a How-to, although if you’d like to double-check and refine this, anybody who’s willing/able to make one can make it.
What might be a good Feature request would be to ask if the UI could specifically lead one through things, however given quite a large backlog, some documentation approach might be faster to get some help out.