EDIT: The error message was changed in 2.0.4.5 beta (and earlier in 2.0.3.12 canary) so you probably don’t need this translation any more, and the version that you delete is the version the message said, for example:
Unexpected difference in fileset version 0: 12/5/2018 6:39:53 PM (database id: 3), found 2 entries, but expected 3
Users of versions without this fix still need to translate, but it’s also possible the version to delete is usually 0.
(prior text)
From looking into the code awhile, I think the number on this message is the internal one, and doesn’t match numbers shown on the dropdown, which based on your 9 versions probably ran from 0 to 8, so asking for 50 probably simply deleted nothing. Is that message still the same (fileset 50 and all)? I couldn’t locate any code which I might persuade to map 50 to one of 0-to-8, but I think you can find it from the database with a viewer. There are 43 rows in the Fileset table on one of my backups, Dropdown shows 0-42, internal ID are 100-142 and mapping is possibly finding the ID from your message, readng a column left, and subtracting 1 from that. EDIT: This is incorrect in the screenshot because the larger timestamp should be at the top and be version 0 in the GUI dropdown. Clicking on the timestamp column can probably sort everything for you, then you need to adjust to 0-based numbers if your particular SQLite browser starts numbers at 1 (as the one shown does).
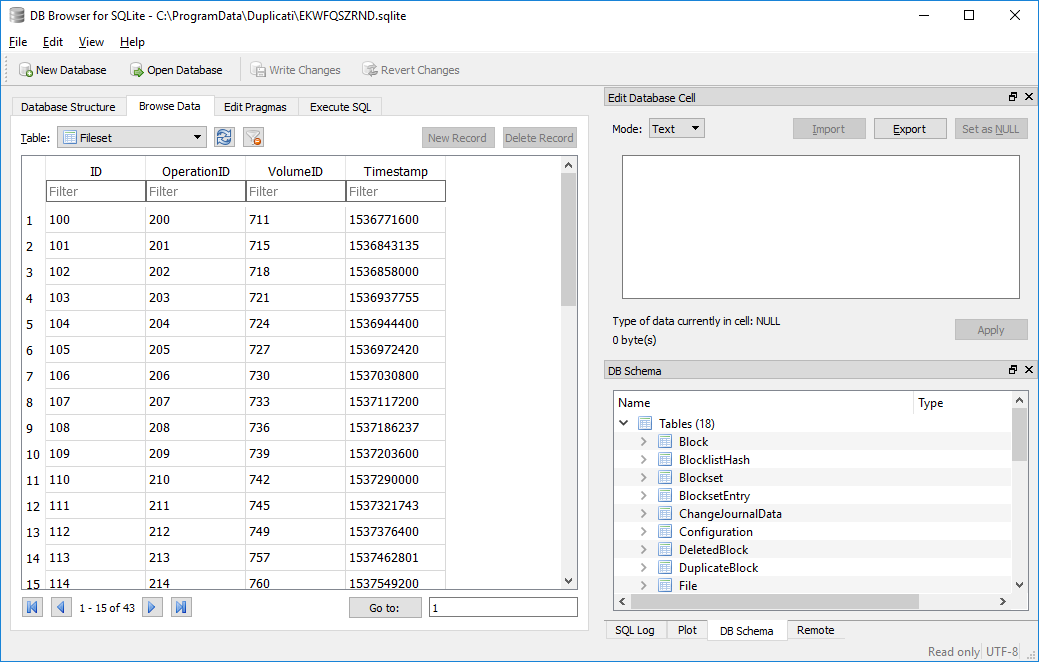
I’ll stop by #4286 where a similar possible mapping problem showed up, to see if anybody’s still set up to test.
Please let me know if you’d feel comfortable with this. Looking at other cases like this, many were resolved by deleting and recreating the database, however your opening remark was that didn’t go well last time you tried.