I am hoping I can get some help here. I am new to Duplicati and I am trying to backup some local files to OpenDrive via WebDav. I want to break it up into 10GB chunks, and I am trying to use the asynchronous-upload-limit option for my job, but it seems to be ignored and keeps using the default value of 4.
I am running LSIO’s Duplicati container and running version Duplicati - 2.0.6.3_beta_2021-06-17
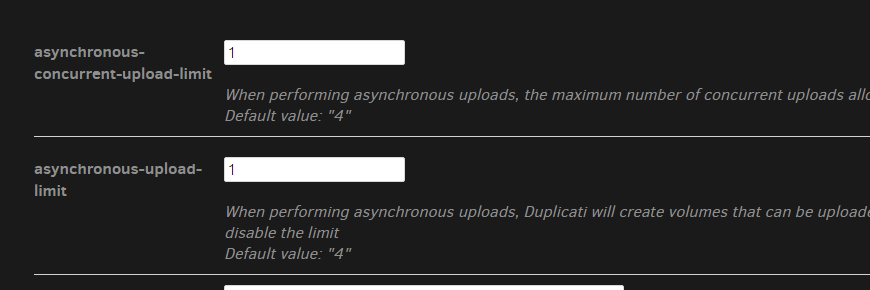
Here are the options I am setting for my backup job:
And here is the /tmp directory in the container where it’s still creating 4 files even though I want 2:
Can anyone potentially tell me what I am missing? Because all the other thread I’ve found say using this option fixed their issue, but I have tried setting it for the job and at a global level with no luck.
Make sure you understand the potentially severe performance implications on restore of doing that.
If the whole backup is large, it can help performance to raise blocksize so that not more than a few
million blocks are in that backup (unfortunately you can’t increase blocksize on an existing backup).
Did you test a value of 1 to see if result changes?
Debugging containers is harder because it’s hard to know what commands it has in it, but we can fish.
Another option might be to use one of the mapped volumes for your tmp folder so as to use host tools.
You might also have more space. I don’t use Docker, but isn’t the /tmp there rather limited in capacity?
That might be 2 variants of 2 files. Can you find any command to check the first few bytes of each file?
Candidate tools would include od, hexdump, dd. Run fuser on dup-* . Try testing with unzip test or list. Decrypt (if you use encryption) with mono SharpAESCrypt.exe (found in the Duplicati install directory).
I’m not sure why your files are so similar in sizes and dates. If you gave the full size in bytes, and used --full-time on ls, that might also reveal the history a little better, e.g. an encrypted version is bigger.
I will look at this specifically blocksize. I want to reduce the number of dup-* files on my remote backend. The source data is approximately 150GB (this is a test run for my bigger multi-TB backup). I also have a local drive that I backup to daily and the sqlite database for this same data locally is 400+MB, so definitely worth looking into. Thanks for this info.
I did this previously and received the same results. I did it again just now and here are some screenshots:
I did not report the original issue, but the latest comment on there is mine, but since I’ve seen other threads where people are successful with this option, I thought I’d reach out here to see if I’m doing something wrong.
I am encrypting these backups, so not sure if one is the unencrypted archive and the other is the encrypted copy, but getting 4 files at the same time still wouldn’t make sense since it would need to create the archive completely before encryption.
Additionally, this docker container image has dd and od on it, but I am not sure the correct command to run to check the bytes on each file
Given those two, od -c /bin/bash | dd count=1 should show start of the file in a binary-safe way.
If file starts with PK it’s a .zip file, and might be temporary, or something about to encrypt and upload.
If file starts with AES it’s the encrypted version. There are other possible types but they’d be less large.
I’m still surprised that they’re that near in time. BTW, leaving off the h on ls would show the actual size where possibly an encrypted version grew by a few hundred bytes compared to its unencrypted version.
And here is the output from the od -c dup-* | dd count=1:
root@826897243fdf:/tmp# for i in $(find /tmp -type f -print -size +100M); do echo "file: $i"; od -c $i | dd count=1; echo ""; done
file: /tmp/dup-1f912de0-006c-4ac7-ac43-4e3a4d7ca36f
0000000 P K 003 004 024 \0 \0 \0 \b \0 321 t 210 T 343 020
0000020 262 \t v \0 \0 \0 222 \0 \0 \0 \b \0 \0 \0 m a
0000040 n i f e s t { 277 { 177 265 R X j Q q
0000060 f ~ 236 222 225 221 216 222 s Q j b I j 212 222
0000100 225 222 221 201 221 221 201 211 201 E 210 241 245 261 205 261
0000120 i 224 222 216 222 k ^ r ~ J f ^ : P 266 264
0000140 $ 315 002 ( 342 224 223 237 234 ] 234 Y 225 252 d e
0000160 1+0 records in
1+0 records out
512 bytes copied, 0.264636 s, 1.9 kB/s
file: /tmp/dup-326d9519-18fa-4559-9b7b-a7396dd961a3
0000000 P K 003 004 024 \0 \0 \0 \b \0 322 t 210 T 255 v
0000020 032 261 v \0 \0 \0 222 \0 \0 \0 \b \0 \0 \0 m a
0000040 n i f e s t { 277 { 177 265 R X j Q q
0000060 f ~ 236 222 225 221 216 222 s Q j b I j 212 222
0000100 225 222 221 201 221 221 201 211 201 E 210 241 245 261 205 261
0000120 Y 224 222 216 222 k ^ r ~ J f ^ : P 266 264
0000140 $ 315 002 ( 342 224 223 237 234 ] 234 Y 225 252 d e
0000160 1+0 records in
1+0 records out
512 bytes copied, 0.372707 s, 1.4 kB/s
file: /tmp/dup-772fdbb4-ebd2-45ca-9504-9a7b52585ed1
0000000
0+1 records in
0+1 records out
8 bytes copied, 0.67692 s, 0.0 kB/s
file: /tmp/dup-2b95249c-ef9d-43a2-af7a-3f0f5bbddd21
0000000 P K 003 004 024 \0 \0 \0 \b \0 322 t 210 T 255 v
0000020 032 261 v \0 \0 \0 222 \0 \0 \0 \b \0 \0 \0 m a
0000040 n i f e s t { 277 { 177 265 R X j Q q
0000060 f ~ 236 222 225 221 216 222 s Q j b I j 212 222
0000100 225 222 221 201 221 221 201 211 201 E 210 241 245 261 205 261
0000120 Y 224 222 216 222 k ^ r ~ J f ^ : P 266 264
0000140 $ 315 002 ( 342 224 223 237 234 ] 234 Y 225 252 d e
0000160 1+0 records in
1+0 records out
512 bytes copied, 0.227438 s, 2.3 kB/s
file: /tmp/dup-51aad63f-afc3-45e5-9500-378e7b061c5d
0000000 P K 003 004 024 \0 \0 \0 \b \0 322 t 210 T 255 v
0000020 032 261 v \0 \0 \0 222 \0 \0 \0 \b \0 \0 \0 m a
0000040 n i f e s t { 277 { 177 265 R X j Q q
0000060 f ~ 236 222 225 221 216 222 s Q j b I j 212 222
0000100 225 222 221 201 221 221 201 211 201 E 210 241 245 261 205 261
0000120 Y 224 222 216 222 k ^ r ~ J f ^ : P 266 264
0000140 $ 315 002 ( 342 224 223 237 234 ] 234 Y 225 252 d e
0000160 1+0 records in
1+0 records out
512 bytes copied, 0.184763 s, 2.8 kB/s
file: /tmp/dup-8d054552-9a0e-4a54-a78f-1d556a042e7c
0000000 P K 003 004 024 \0 \0 \0 \b \0 322 t 210 T 255 v
0000020 032 261 v \0 \0 \0 222 \0 \0 \0 \b \0 \0 \0 m a
0000040 n i f e s t { 277 { 177 265 R X j Q q
0000060 f ~ 236 222 225 221 216 222 s Q j b I j 212 222
0000100 225 222 221 201 221 221 201 211 201 E 210 241 245 261 205 261
0000120 Y 224 222 216 222 k ^ r ~ J f ^ : P 266 264
0000140 $ 315 002 ( 342 224 223 237 234 ] 234 Y 225 252 d e
0000160 1+0 records in
1+0 records out
512 bytes copied, 0.014148 s, 36.2 kB/s
Well, those sizes being more than slightly different, plus them all being .zip files shoots down the idea of some of them being encrypted .zip files. So this might actually not be working. There IS that open issue. Maybe someday some developer can go in and look, however more developers are very much needed.
EDIT:
So if nobody can figure a way to configure around the possibly broken option, you still have the option to configure Duplicati temporary folders in Docker and your backup remote volume size to avoid issue.
Old post, but since it hasn’t been mentioned yet: For me, asynchronous-upload-limit is also being ignored. However, concurrency-compressors seems to work like asynchronous-upload-limit. In my case, the number of temporary files created is always equal to asynchronous-concurrent-upload-limit + concurrency-compressors.
--asynchronous-upload-limit: The number of concurrent uploads
--concurrency-compressors: The number of concurrent zip files
The logic is that Duplicati will create one temporary zip file for each --concurrency-compressors and all these are “temporary files” that will gradually get filled during backup.
Once a zip file reaches the size limit it is passed on to one of the --asynchronous-upload-limit uploaders. During transfer the temporary file stays on disk, and only when it is completed will it be removed.
Because the temporary file is “passed” from the compressor to the uploader, it is not taking up a compressor, giving the equation you found:
If you want to see this effect, you can also set --asynchronous-upload-folder to a different folder, so you can monitor the temporary files that are being built separate from the ones that are being uploaded.
There is an option that is supposed to fix this: --synchronous-upload. The intention of this option is to not progress from compression until the file is fully uploaded, so value for --concurrency-compressors is defining the total number of temporary files.
Unfortunately, this option is not currently working due to an “optimization” that attempts to increase upload throughput. It will hopefully be fixed soon, with a rewrite of the uploader system.