I could be completely off on this, but assuming I’m reading the code right, if no records are returned from the query then the GetBlocklists method in which it’s being called ends up not returning a Tuple at all.
From what I can tell this method is called from both RecreateMissingIndexFiles and RunRepairRemote both of which use the result of GetBlocklists in a foreach loop, but the RecreateMissingIndexFiles files loop is NOT in it’s own try / catch block, however the caller is in a “Fatal error” try / catch so from what I can tell any actual error should be getting handled.
Might it be possible to inject a few diagnostic profiling log postings into the canary build to try to figure out where this is going wrong? I’m not a C# guy and don’t know how the logs are being processed. Just seems like a good idea from the outside.
One more possible bit of info. I’m not sure whether this is a standard message or built from current operations, but I got this when pressing the “X” on the status bar.
Duplicati seems to be indicating that it’s uploading something. No evidence of it, though.
That is a standard message whether an upload is going or not.
What it’s really asking is “Should I ABORT what I’m doing RIGHT NOW” (will generate a System.Threading.ThreadAbortException error message) vs “Should I kindly stop at my next opportunity” (generally no error message generated, but might be a few minutes before it ACTUALLY stops).
I’ve tried answering the question both ways and it doesn’t stop. As I said, it’ll run till the power goes out.
Where in the project is the source code for the GetBlockLists function and its calling functions? I’m just scanning from github and haven’t installed the IDE to make searching easier.
If you search for GetBlockLists (upper left of screen) at the Duplicati GitHub page you should find that the tuple version is in Duplicati/Library/Main/Database/LocalDatabase.cs.
Add my name to the list of people experiencing this problem.
My backup set is ~3.5TB. I’ve had the initial backup running for 6 days, but after a reboot I am stuck in Verifying Backup Data, which has now been running for about 12 hours.
I am desperate to get this fixed soon, as I am trying to get all of this backed up within the same Comcast billing cycle. If this issue causes the backup to head in to May, it’ll cost me another $200 in overage charges
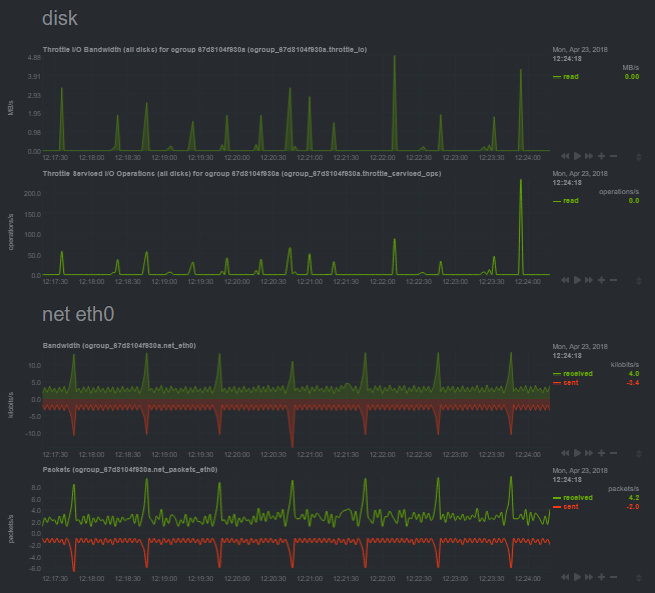
Is there absolutely anything I can do to help diagnose this issue? My symptoms are the same as everyone else: one full CPU core pegged and it doesn’t respond to any stop commands. I am running inside a Docker container, and I can see that it’s doing only a very small amount of disk and network I/O:
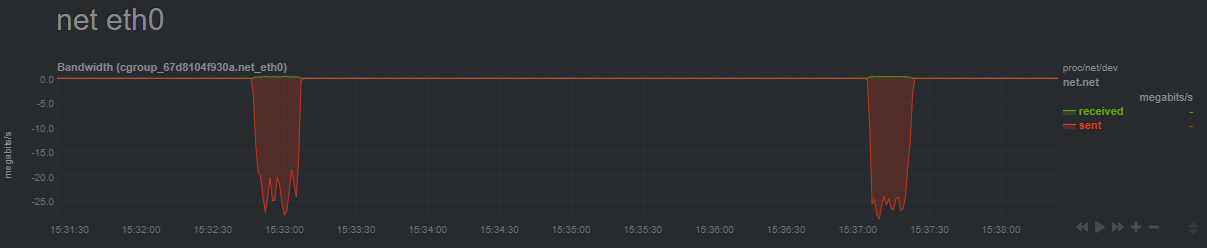
Edit: Update: After about 16 hours, the backup has continued, but it’s not going well. The backup is only sending up chunks once every 5 minutes or so, with huge periods of inactivity between them, as you can see in this screenshot:
The CPU is pegged the whole time, so it does seem to be doing something. For the first week or so of this backup, I was getting a constant 3MB/s upload, which is what I have the cap set to, so it does seem like something changed.
If so, I suspect your initial 3MB/s upload speed (which I assume was fairly constant / frequent) was because pretty much every block found needed to be backed up.
But as more and more blocks are sent, it becomes more and more likely that new blocks are duplicates of existing content so you could now be spending more time identifying duplicate blocks than uploading new ones.
If that’s what’s going on, then there’s not much you can do to speed things up. However, if it’s just a general performance issue related to compression then you could try using a lower compression setting (of course that means more files and this more bandwidth and destination requirements).
At this point it’s probably to late to try, but if you have the local storage you could “seed” your entire backup to a local drive then manually upload it to your destination during whatever billing periods bake sense. Then point your backup job from the local destination to the cloud one and let it continue with deltas only from there.
Oh - and you didn’t mention what version of Duplicati you are using, but a new Canary was just released with a lot performance improvements. Of course they’re mostly designed around concurrent processing and since your CPU is already fully utilized it may not make a difference…
Thanks for the feedback! I think your analysis here makes a lot of sense. I’m letting it chug away, and reducing the number of files in my backup by a few hundred thousand by pre-compressing hundreds of Audacity projects (which store all audio in 1MB chunks when uncompressed!) I am hoping that’ll help out some. I’ll probably have to pay another month of Comcast overages, but it if gets me versioned, secure, self-managed backups at the end of all this, it’s worth it!
The suggestion to use a local staging location is pretty brilliant though!
Thanks so much for the great work on this program.
Pre-compressing files should help with Duplicati compression overhead as it won’t re-compress them.
And it won’t skip the block hashing, but a smaller file means fewer blocks to have to process so that should help a little bit.
If you’re not time constrained you could consider stopping the backup when you get close to your monthly limit then manually start it up again the next month.
Alternatively, do the math for how much bandwidth you want to let Duplicati use per month, divide that out to about how long Duplicati runs (much easier if your computer is on all the time) and put in a bandwidth limit so your backups “can’t” use more bandwidth than you want in a particular time period.
I’m glad you like what you’re seeing in Duplicati, good luck with your bandwidth!
I am also stuck now with Verifying Backend Data.
My Backup Set is ~3TB and uploaded to Jotta. The files are rather large between 5GB and 40GB or small <500kb. The database file is 5.5GB big.
The initial backup was now problem and done in 6-7 days. The following incremental backups were done properly and did not take longer than 12 hours including upload. But the last increment got stucked. After 24 hours I rebooted my machine and started over. I set the –no-backend-verification=true but it had no effect. Now I am stuck again.
I am running 2.0.3.13 canary (also happend on 2.0.3.5) on a Qnap NAS.
mono-sgen process is utilizing one core completly but is also sleeping.
Then there is a kernel process which sometimes peaks, which I saw on working backups to be the decryption and/or check.
The last entry in the log (profiling)
Nov. 2018 18:56: ExecuteScalarInt64: SELECT COUNT(*) FROM “Block” WHERE “Size” > 102400 took 0:01:19:24.899
My second largest set with 2.31TB is just working fine (as of now).
I read in this thread, that particular large backup sets are effected mostly. Is there a limit of 3TB I am not aware of?
So I aborted the backup job because literally nothing happened. Even the disks spinned down.
I was curios and wanted to know what happened, when I start Verify Files. And to my surprise it just finished fine in a reasonable timeframe.
So I found something strange. Maybe that it is why the verifyinig of the backend data fails.
Duplicati says my last sucessfull backup was on 2018-09-24. But if I look into my destination folder, there are files uploaded on 2018-10-05. And it is definitely another version from 2018-09-24.
I tried to repair the DB from scratch but the verifying still fails.
What versions do you see listed if you try a Restore?
I’ve got a job that frequently has errors during the post-backup processing (such as retention policy cleanup) so the BACKUP works (is restorable) but the JOB fails (not listed as a successful backup).
Sounds like you’re having the same thing - the backup itself succeeds but the subsequent verification step fails cauinge the entire JOB to be declared not-successful.
I suspect if you set --backup-test-samples=0 your error will stop happening and jobs will be flagged as successful. Note that , if that happens it just confirms where the error is happening (during verification) and hasn’t actually fixed anything!