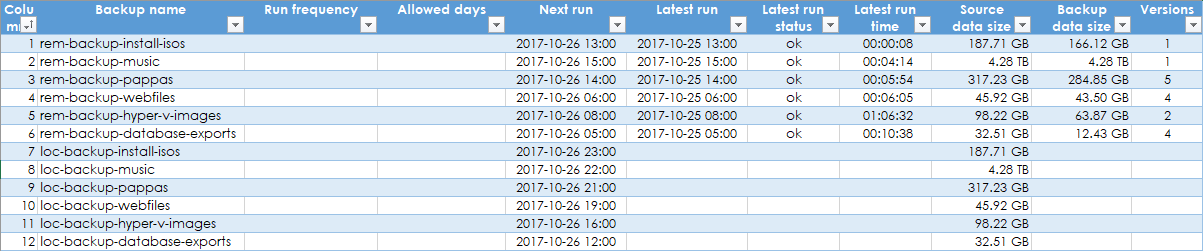
All my backup jobs to the local backup server have now run a few times each. So I added all the (identical) send to offsite backup jobs. But I needed to see a sorted list of scheduled times to see if I overlapped some of the jobs. So I went the quite convoluted way of copying the text on the Duplicati web page which lists all the jobs, then copied this to a text editor to change some newlines to tabs and so on and then import it all into excel. Yeah a bit crazy
It would be really cool if something like this could be a simple data table view into the Duplicati database within the Duplicati interface somehow. I added some dummy columns to my excelsheet just to show what I was thinking. You get a good quick overview when you can sort on things like next run time, size, latest job status, time latest job took and so on…
I’m playing around a bit with python and querying the db’s to get some statistics. I might include the above, but all is done in my free time which actually does not exist…
I thought the main db with this data was encrypted and password protected someway? I didn’t look into it very hard obviously haha.
So just straight up python and sqllite? I will definitely look into this then! Nice! Could you possibly consider sharing some initial code so I save time setting up the basics to connect to the db?
Very basic script for now… It queries the config db to get the name & db path of each jobs. With those db’s, it checks the logs to see how many files have been added/deleted/examined. First goal is to put this in a google chart to display for each job.
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import sqlite3 as lite
import cgitb; cgitb.enable()
import datetime
import sys
def print_results(obj):
for i in range(len(obj['Timestamp'])-1):
print "[ new Date("+obj['Timestamp'][i]+"000), "+str(obj['AddedFiles'][i])+", "+str(obj['DeletedFiles'][i])+", "+str(obj['ExaminedFiles'][i])+"],"
eventList = []
con = lite.connect('/root/.config/Duplicati/Duplicati-server.sqlite')
with con:
cur=con.cursor()
sqlCommand = "SELECT Name, DBPath FROM Backup;"
cur.execute(sqlCommand)
arrayofresults={}
while True:
row = cur.fetchone()
if row is None:
break
#print format(row[0]) + "\t" + format(row[1])
backup_name = row[0]
con2 = lite.connect(row[1])
arrayofresults[backup_name]={'Timestamp': [], 'ExaminedFiles': [], 'AddedFiles': [], 'DeletedFiles': []}
with con2:
cur2=con2.cursor()
sqlCommand2 = "SELECT Timestamp, Message FROM LogData;"
cur2.execute(sqlCommand2)
while True:
row = cur2.fetchone()
if row is None:
break
result={}
result_rows = row[1].splitlines()
for s in result_rows:
result_split = s.split(':')
if len(result_split)>1:
#print "item:\t"+result_split[0]+"\tvalue:\t"+result_split[1]
result[result_split[0]]=result_split[1]
if result.has_key("Message"):
break
if result.has_key("ExaminedFiles"):
#print format(datetime.datetime.fromtimestamp(row[0]).strftime('%Y-%m-%d %H:%M:%S'))+result["ExaminedFiles"]+result["AddedFiles"]+result["DeletedFiles"]
arrayofresults[backup_name]['Timestamp'].append(str(row[0]).strip())
arrayofresults[backup_name]['ExaminedFiles'].append(result["ExaminedFiles"].strip())
arrayofresults[backup_name]['AddedFiles'].append(result["AddedFiles"].strip())
arrayofresults[backup_name]['DeletedFiles'].append(result["DeletedFiles"].strip())
#arrayofresults[backup_name]["ExaminedFiles"]=
print backup_name
print_results(arrayofresults[backup_name])
I’m the same way and like to space out my jobs (not nearly as many as you have though). But for those less OCD, I’m pretty sure there isn’t any real negative to letting them overlap. The next job will start as soon as the previous one finishes. So long as you have enough time in any given backup cycle for everything to complete.
When I run the backups the first time they take a long time to copy everything over, one backup job runs for 4-5 days first time it’s run. During that time exactly what you say happens. But it seems the queue only holds the last scheduled run for each job which is perfect, no duplicate jobs in the queue.
Traceback (most recent call last):
File "runme.py", line 21, in <module>
cur.execute(sqlCommand)
sqlite3.DatabaseError: file is encrypted or is not a database
And obviously it’s not your code. I tried it with my main servers Duplicati-server.sqlite, my desktop Duplicati-server.sqlite and again with a totally fresh install of Duplicati.
An overview is definitely needed. I permanently find myself starting a manual job, with first starting the server. Then it insists on starting old jobs. I’m aborting the unknown number of jobs then. It’s pretty intransparent.
Yeah, I found my way around it with --unencrypted-database
I have a complete sortable table view done now. Currently I actually run it in Python with wsgiref.simple_server as a webserver with just a few extra line of code to test it.
The question is if anyone else would like to use it and if so what the best way to distribute the functionality would be. I saw that Duplicati is written in js so maybe I should have written it in that instead… well well.