Would we really have to cheat and manipulate filenames? How about we let Duplicati generate filenames like it always does, but then run the name through a hash function. Take the the last 2 or 3 characters (depending on how many folders you want to end up with) to determine where the file should be placed on the back end.
Nature of hashing functions is that the distribution should be even. The files would end up be splitting into 16 ^ X folders, where X is the number of characters you pull off the end of the hash.
Two characters = 256 folders
Three characters = 4096 folders
Edit - well maybe if they are completely random already it’s unnecessary to run them through a hash function. Just use the last 2 or 3 chars of the original filename lol - before the .dblock.zip.aes of course.
Edit2 - perhaps it would still be useful for dlist files which do not have random names.
I think I now have the logic and code worked out for the directories.
I was thinking it would be a benefit to be able to calculate the path using the filename. I did this in my first iteration of creating subfolders.
Though now I’m not sure what benefit of being able to calculate the existing path. The reason being that I’m storing the paths are in the database. This entire calculation only occurs when a volume file is being uploaded to the backend. At all other times the files are looked up in the database.
For retention, there is little to be done to avoid directories becoming sparse. But a fix for that may be a job which consolidates files from sparse directories. This job could be part of the retention checking.
This would result in thousands of folders that contain only one file. If the number of folders would be limited (using only the last 2 characters of a filename, max 256 folders) would limit the total backup size too much.
I was thinking of a way to create about 3000 folders that fill up to about 3000 files, using no more folders than needed.
A random filename would distribute the files over too many folders.
One benefit is that no changes are required to the local db structure.
Another benefit could be that filling up sparse folders could be done during backup operations (just generate a filename that “fits” in that folder and upload it, instead of downloading and re-uploading during a compact operation). But I guess somehow that could be implemented using your idea too.
I don’t need to modify the db structure. The path is added to the filename.
Any subfolder solution will need to deal with sparse folders. Given that the db holds all the filenames and paths we can calculate where to place additional files and target sparse folders, if we want that as a solution.
The important part, to me, I have the subfolders coded and working; and it works with existing backups. The algorithm to place folders can be easily modified or replaced even with existing backups. So later on any other ideas for file placement can just be added in.
I think I have the algo done for max filling folders with a flat structure.
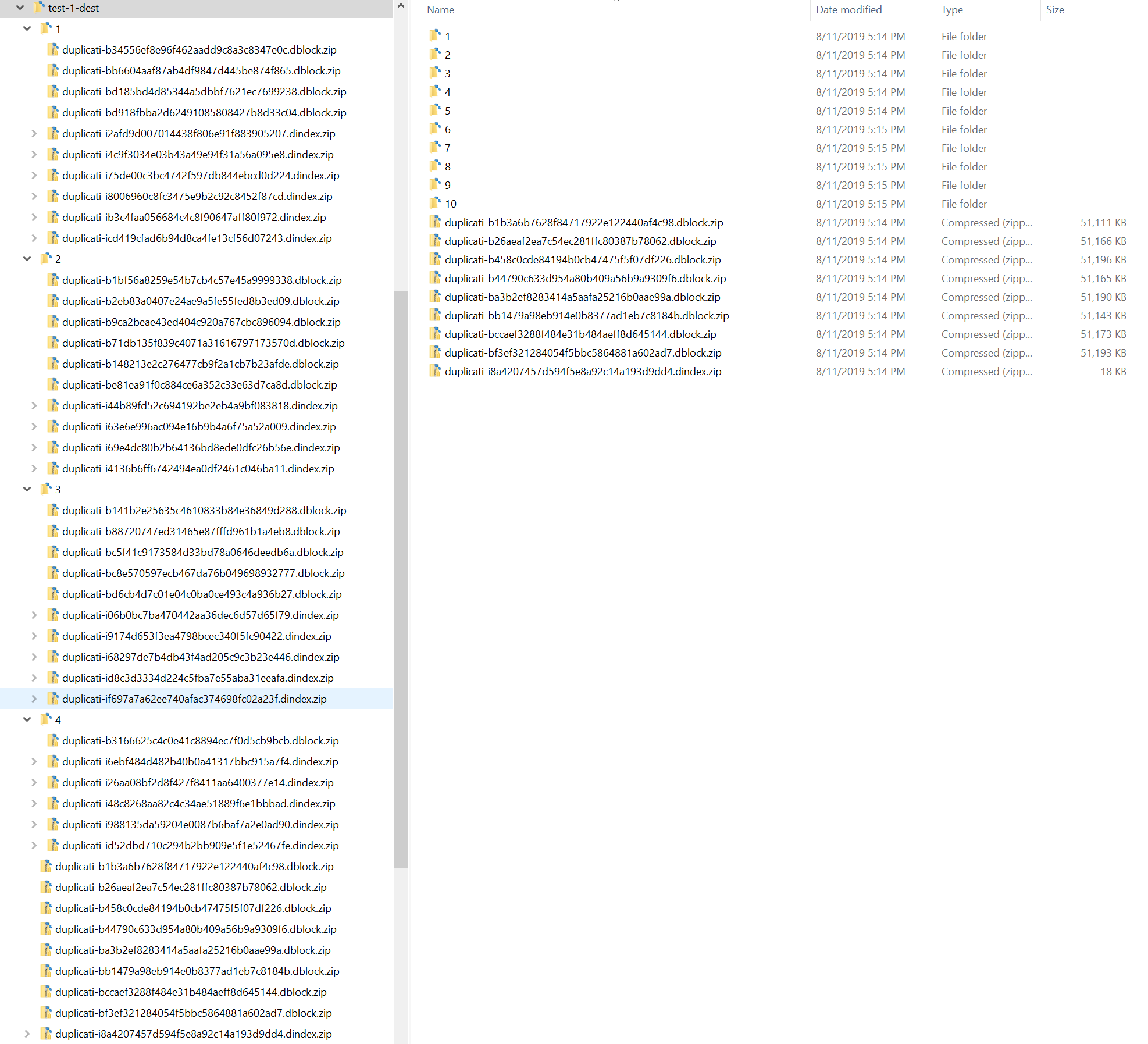
I’m going to start with 2000 files per folder and 1000 folders per folder.
The first 2000 files go in the root “/” directory. The next 2000 files go in “/1/”.
The 25,654,396 file goes in “/12/826/”
So this seems to reach the goals. It is pretty flat, works with the limit of 5000 items per folder, and supports a lot of files.
I just ran a test with 10 files per folder and 10 folders per folder on 6GB of data at 50MB blocks.
Looks like this approach works great, even for existing backups without subfolders. Great work, love it!
Can I make a few suggestions?
To get backend files and folders sorted nicely, leading zeroes could be added to folder names: 0001 instead of 1.
In Duplicati, filenames have a prefix, a dash and a single character to indicate the filetype. All files are preceeded with duplicati-b or duplicati-i by default.
To make clear that a folder contains Duplicati backup files, the folders could have the same prefix: <prefix>-d (example: duplicati-d0001).
Isn’t the 2-level tree a bit overkill? If you just stick to 2000 folders in the backend root with 2000 files per folder, you can backup up to 100 TB per backup job when using the default 50MB DBLOCK size. If you increase this to 4000 files per folder, the max is 200 TB (2000 folders * 4000 files * 25MB average file size). I guess this should be enough for any backup job.
You could make a 1-level structure (see above) default and introduce an advanced option: --folder-depth=n (default 1). Folder depth could be set to 0 for no subfolders and 2 for an extra tree level for superlarge backups.
Other useful advanced options that could be added: --max-files-per-remote-subfolder=n (default 2000 or maybe more). Can be used to set the number of files in every folder. --max-folders-per-remote-subfolder=n (default 2000). Can be used to specify how many subfolders are created before a new parent folder is created.
Thanks. And the options are definitely a good idea. I used your suggested parameters.
“2-level” well… the logic is already done. And it isn’t just 2-level. It will go indefinitely. The folder structure will not be a bottle-neck.
For most users they’ll likely never branch out of the 1st level of folders.
Regarding file sorting and 0001, why even the need to have them sorted?
The filenames are pretty long, which is helpful to keep them unique in a single folder. But at 2000 files per directory the filenames can likely be shortened and thereby reduce the database size. We would want to try and keep the filenames long enough to not have collisions since we might want to reorganize the files in a future process. Though perhaps the filenames could actually grow in length as the number of files increase since I already have the total file count handy in the process. Something to think about further.
Not a special reason, it could be handy when accessing the remote files using a file browser instead of the Duplicati software. For example, if you want to download the files to/from local storage for migration to another backend, of for disaster recovery tasks.
Apart from that, it just gives a cleaner look.
The filenames contain 32 random characters, because it’s a standard GUID.
But all characters (except the 13th) are random, so the filenames could be truncated to save some space in the local DB. I don’t have a clue how how much the db size would decrease because of shoreter filenames.
So when a backup runs, it is not creating these files in an incredibly excessive speed. It isn’t a bottle-neck. So I think we can shorten the name, run a check of the database for a name collision, and just use shorter names. Thoughts?
Either way… it isn’t really a pressing issue… but a nice-to-have.
Closing this due to lack of activity. We can revisit this later if necessary.
It seems it’s on hold. Its developer stopped, so it may need a restart. You?
I don’t think the need has gone away, but there are lots of competing ones.
I think (but am not sure) that the current developer team is lower on web skills than C#.
https://github.com/duplicati/duplicati/issues?q=is%3Aissue+is%3Aopen+label%3AUI
has some issues that a skilled web person (I’m not) could probably resolve fairly easily.
I think there are some ways to keep autofill out of fields. One issue is we do want stars.
The problem possibly comes from being a single-page web app. It confuses browsers.
UX category and to some extent Features category have other things needing web skill.
At the moment, there are resource limits in pretty much all skills, but I hope it improves.
Being all-volunteer, Duplicati progress relies on whatever its volunteers are able to do…
This feature appears to also be very useful for non-remote devices. I have an external hard drive with a FAT32 file system (that’s how it came) and Duplicati backup usually stops working after 11 backups, for all I know because the maximum number of files in the directory is reached.
So this feature would help me a lot. This would also mean that the sub folder functionality should also be implemented for non-remote targets.
Looks like FAT32 supports 65536 entries in a single directory. From what I can see a file takes 1 entry plus 1 more for every 13 characters in the filename. Duplicati filenames (with default prefix and with encryption) are up to 58 characters long, which I guess means they would consume up to 6 directory entries each. So maybe about 10k files maximum? Does that sound like what you have in your FAT32 target before Duplicati stops working? How large is the source data being protected?
The source is about 300GB. One backup that stopped working has 10924 files, so your assessment might be right. The other stopped at about the same number of backups, so it could be a similar number of files. So yes, that could be the issue. I got different errors with the first stalled backup and the second, gut that could also be because of different versions of Duplicati.
Does source files area change heavily from backup to backup? You can get a sense for that in the growth of the backup on its home page overview where it has backup size and number of versions. More is in job logs, such as Source files statistics in main page, and various BackendStatistics.in Complete log.
On Options screen 5, you can limit your versions or thin with age. More importantly, you can increase the Remote volume size probably quite a bit. The default 50 MB might suit typical home Internet connections however with a local drive your transfer rate is probably far higher, so you can worry less about larger files.
If you have large datasets and a stable connection, it is usually desirable to user a larger volume size.
You can change this size (unlike the blocksize) whenever you like, but existing volumes aren’t immediately grown. If I recall correctly, the decision to compact will decide the old volumes are underfilled, so will swing into action to cure that. This may take awhile to do all the downloading and uploading, so pick a good time.