The only issue with Cloudberry is the cost of the software and that you need to pay for it on each client machine you run it on. It is also limited to 5TB backups. You can use the free version but with no encryption or compression and are limited to 200GB and can’t run it in a domain. Otherwise it’s a very nice app.
I’ve investigated dozens of alternate solutions. The problem usually is:
- Bad software
- No efficient de-dupliation
- Lack of proper encryption
- Per client pricing
- Expensive storage
Second option after Duplicati was actullay SOS Online Backup. You only pay for storage. But it’s still problematic, if you’ve got databases sized at terabytes and the de-duplication is done on server side. SOS Online does provide proper client side “pre-cloud” encryption as option.
If I would have found perfect option for Duplicati, I wouldn’t be using Duplicati, because there are serious problems as mentioned. But on the paper (excluding bugs) the software is absolutely awesome, features are really good.
I wouldn’t bother whining about problems, if it wouldn’t worth of it. 
That sounds useless… Encryption effectively scrambles the data ruining any deduplication potential server side.
Keep in mind that almost all posts here are focused on fixing an issue, so you don’t see anything about the thousands of backups a day where it all works.
I can provide some numbers for that. At duplicati-monitoring.com, we have received more than half a million Duplicati backup reports within the last year. 84% were reporting successful backups:
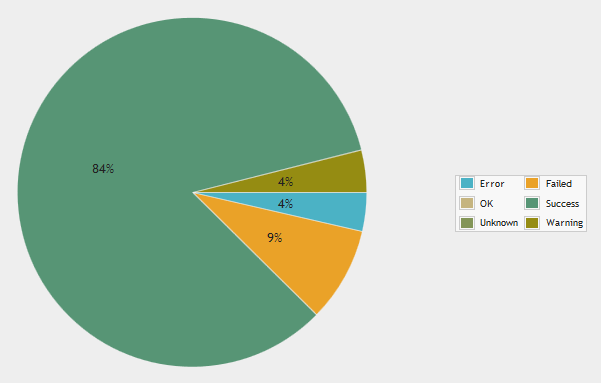
Of course this does not tell you something about restore problems etc. but it may give you some idea. I guess most failed backups are not due to a Duplicati bug I guess, but due to issues like backing up to a USB drive that is not connected, remote storage quota exceeded etc.
2 Likes
Thanks pro that pie graph.
I think that ratio of successful backups can be little bit misleading.
For example, I have backup job that work’s for more than year, but in last week I had reboot during backup.
When I was verifying and purging, I find out that also some old couple months unmodified backup files have wrong hash.
When I was purging those files I encounter (bug from 2016 still open…)
and DB recreate failed.
So one interrupted backup was enough to completely kill my backup and I will be probably forced to start from zero.
I think Duplicati can be a good tool for production, but it must not be the only one. It’s still too fragile
2 Likes
Just about “my problems”. I’ll run 100+ different backup runs daily. And 1000+ weekly. As well I try to test the backups around monthly, I’ve fully automated the backup testing.
I see problems every now and then, and I’ve got automated monitoring and reporting for all of the jobs.
But there are fundamental issues, and things which really shouldn’t get broken, do get broken, as well as the recovery from those issues is at times poor to none. -> Which just means that over all reliability isn’t good enough for production use. You don’t ever know, when you can’t restore the data anymore. Or when the restore takes a month instead of one hour and still fails.
But many of those issues are linked to secondary problems. First something goes slightly a miss, and then the recovery process is bad, and that’s what creates the big issue. On production ready software both of those recovery situations should work. FIrst the primary issue should be deal with efficiently and automatically, and even if that fails, then the secondary issue process should be also automated or manual, but work in some adequate and sane way.
As example if we use file system or databases. If system is hard reset, journal should allow on boot recovery and even if that fails, there should be process to bring the consistency back, even if that wouldn’t be as fast as the journal based roll forward or backward. And if the software is really bad, then the file system gets corrupted during normal operation even without the hard reset. Currently the backup works out mostly ok, but you’ll never know when it blows up. And at times it’s also blown up without the hard reset. Which makes me really worried. As I’ve mentioned. As well as recovering from that, has been usually nearly impossible.
Sure I’ve had similar situations with ext4 and ntfs, but in most of cases, that’s totally broken SSD or “cloud storage backend”. And it’s joyfulyl rare, that file system becomes absolutely and irrecoverably corrupted. We’re not there with the Duplicati yet.
Anyway, as mentioned before. Duplicati features are absolutely awesome. If I wouldn’t really like the software, I wouldn’t bother complaining about the issues. I would simply choose something different.
it would be nice to be able to recover data even with a corrupt archive, at least to be able to recover all the good stuff.
I for security use cobian for full monthly backups, and duplicates2 for the daily
I think data are almost always recoverable via Duplicati.CommandLine.RecoveryTool.exe
It’s not pleasant and fast, but it works.
For example in my case when backup was interrupted and I could not backup/restore/recreate DB - I was able to recover data via that tool without problem or warnings.
It’s also usually always possible to restore “directly from files” as that creates a new simpler database.
Yes, but that could take weeks or months, that’s the problem. Even with quite small backup restore isn’t completed in a weekend.
Sometimes restore times are quite critical for production systems. It won’t help a lot if you’ll tell the customer that the system will be back in a month. Ok, it’s positive thing if the restore works, “nothing is lost”, but it’s still a huge mess. But it turns even nicer, if after that month you’ll find out that the restore actually failed. - Ouch!
yes, it’s not nice, I do backups on ftp WITHOUT encrypting anything, I hope that in case of disaster it will be faster to recover.
From what I understand the safest combination might be store all versions and use –no-auto-compact=true.
In this case Duplicati should not touch backups created in the past - so older backups should not be corrupted if some problem occurs.
Transaction compaction doesn’t cause any issues, if it works correctly. There’s nothing new with GC processes, and those won’t cause data corruption.
Also situation where data blobs and local database are out of sync, is recoverable in logical terms, but I doubt that Duplicati’s code is able to do it correctly.
As programmer, I understand that recovering from some cases is way annoying, but as data guy, I say of course it should recover because there’s no technical reason why it wouldn’t be possible.
Example cases, which are annoying to deal with, but technically shoudln’t be a problem at all:
- Backup local database
- Run full compaction
- Restore old database back
Bit different approach to the artificially created mismatch:
- Backup backup files in the remote storage
- Run full compaction
- Restore backup files in the remote storage
In both cases, restoring the state in the local database and checking backup integrity should be completed, because now there’s clear mismatch between the local database, and remote files.
Depending on recovery codes quality, such situation causes “total failure” or just slow recovery without problems. Any properly working production quality software should be able to recover from that. Basic works if it happens to work, software says, yuck something is wrong and that’s it. In worst case some ultra badly coded program, could just continue working as normal, but restore would fail.
When working with production systems, recovery from different kind of problems is very important. Sure, it might be needed rarely, but when it’s needed, it’s really needed.
but if I make a backup of the duplicate folder including the local dbase with cobian backup once a month, could it be a better recovery solution?
I thought this too in the past, I have daily backup of Duplicati DB files, yet in my last problem when backup was interrupted by backup, it did not help me - even if I use the older DB, I have the same unresolved errors.
That’s the reason I thought that –no-auto-compact=true is best for reliability of backup.
If compacting is disabled and I have backup of DB, then i case of problem I have to only delete new backup files and restore DB to have backup in working state.
Compaction doesn’t destroy any data, except it removes expired data. The data is still present in the new files, just as I described in my earlier post.
I hope they solve these small problems of recovery, I like the program a lot and it’s a pity that development stops
Just so nobody is confused, development hasn’t stopped, but the primary dev is very busy and as with many open source development projects the availability of other contributors varies greatly.
I agree there are items that need to be resolved and appreciate your, and everybody’s, patience as they are addressed. ![]()
1 Like
perfect, good job
Valerio
Today I decided to do DR test - I wanted to simulate a total loss of my data center.
I got myself a brand new Azure VM, installed Duplicati and started following my DR plan. Its first step was to recover a few folders (we are talking tens of files and megabytes in size) that would facilitate the rest of the recover process. It has been over 12 hours now, I am still nowhere with that first restore due to UI bugs and I am in the process of giving up for the day and going to bed.
I think the next step in my DR planning will be to start looking for another solution…
Not sure what happened to Duplicati over the last year or so, but its overall quality has gone significantly down 