Hello,
I’ve got a serious problem with Duplicati that is currently preventing me from running any backup operations, and that so far I have been unable to either fix or work around.
My backups worked fine (2.0.3.3 beta on Debian 9 x64, to B2 backend, 1.2TB backup size, 1.4TB in the data store) until 28/12, when I got the following error message:
System.IO.InvalidDataException: Found inconsistency in the following files while validating database:
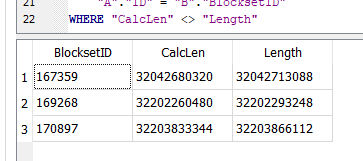
/home/shares/abc/computers/Applications/backup.ISO, actual size 6039240704, dbsize 6039138304, blocksetid: 254312
. Run repair to fix it.
Attempting to repair the database does nothing:
Duplicati.Library.Main.Operation.RepairHandler-DatabaseIsSynchronized]: Destination and database are synchronized, not making any changes
I attempted to rebuild the database, but it was going to take so long (1MB completed after about an hour, for a database 6GB in size) that I cancelled the operation and restored a copy of the previous database.
I upgraded to the latest beta (2.0.4.5_beta_2018-11-28) but this has not helped at all.
I successfully attempted to use the CLI tool to list-broken-files, it lists the above file (and only the above file) in all backup sessions.
However, when I attempted to use the CLI tool to purge-broken-files, it fails with the error message:-
root@moriarty:~# duplicati-cli purge-broken-files “b2://bucketname-backup-shares/moriarty/shares?auth-username=censored&auth-password=censored” --dbpath=/root/.config/Duplicati/SSUBISBTXT.sqlite
Enter encryption passphrase:
ErrorID: PassphraseChangeNotSupported
You have attempted to change a passphrase to an existing backup, which is not supported. Please configure a new clean backup if you want to change the passphrase.
This error is completely nonsensical, in no way I am attempting to change any password, the password is definitely correct (cut & paste, not typed, and in any case it works with the list-broken-files command).
Essentially, I’m out of options to fix this thing and get my backup running again. Aside from the fact that Duplicati has somehow lost data on the data store, and thus destroyed the backup of a file, it is now failing to fix the resulting mess and preventing me from backing up at all.
Any help that anyone can offer at this stage would be gratefully received.
 )
)