- Recreate Database was an attempt to prevent problems that have occurred earlier when I restore a drive image backup of the Ubuntu OS partition.
- Since this is the 3rd time in a week that I try to recreate the database, BackBlaze might have turned down the download speed.
- My CPU is working quite hard: 60 - 90%.
- I have set log level to ExplicitOnly, which produces very large amounts of log info each 2-5 minutes… But not always containing any “Unexpected changes”.

Was that normal restore or Direct restore from backup files? What sort of problem did it get?
You posted a very small sample, but it looks like download wasn’t a big part of the time taken.
I suppose to see the overall rhythm, Verbose might be easier. Go detailed for additional detail.
Is 2-5 minutes the typical interval between downloads? There’s a lot of processing of each file.
Look for the times. In your earlier small post, you had an SQL operation shown with Starting
that never showed its took time. All of this processing can use some CPU and disk I/O time…
How big is the backup or its source data? If over 100 GB, did you scale up blocksize to help it?
EDIT:
Once you look at Verbose log and figure out your average rate per dblock searched, you could
attempt to forecast completion time, although something wrong with the backup that’s causing
extensive search. Duplicati doesn’t detail its reasons (maybe it should), especially at 90% spot.
There’s also no guarantee that the exhaustive dblock search will find all the data it’s looking for.
Special tools and procedures can try to analyze further, but first let’s hear about prior problems.
I am talking about a drive image restore, which means that EVERYTHING on the Ubuntu OS partition is deleted.
Earlier I have moved the Duplicati database from that partition to the data partition, but that didn’t work. Duplicati apparently still kept part of the database on the Ubuntu OS partition, so I had to recreate the database anyway…
I think I will leave my PC for a few hours, and then come back to see if there is any progress…
which wouldn’t be with Duplicati, as Duplicati doesn’t do drive image backup or restore – it does files.
Databases are in ~/.config/Duplicati where ~ for root (if that’s what you run as) might be separate from other non-root user locations. I don’t know how that fits your partition plan, but that’s how it should go.
Databases would be Duplicati-server.sqlite for job configs, and random-letters.sqlite for job databases. Preserving old DBs when restoring from an old image was a good idea – it needs to match destination.
In lack of such a current database copy, Recreate is what you’re left with, so it sounds like things were running OK with Duplicati until Recreate didn’t finish nicely? No prior history of earlier Duplicati errors?
If not, then I guess you either monitor progress and estimate completion (or note any remaining errors),
or if you have some extra disk space you can download the relatively smaller dlist and dblock files for a Python script to examine to see if it can see a reason why Duplicati is still looking (hard) for something.
It was several years ago I had problems with Duplicati, and primarily because I restored drive image backups of the Ubuntu OS partition (using Paragon HD Manager 16 Basic) and thus messing up things by suddenly having an old local database…
There are some open issues on the corruption one can get if one runs repair in such a situation.
I’m not certain that’s relevant here, but it might be if it’s the same backup destination from mess.
Add safety check to repair that prevents deleting unknown new backups #4968 is a fix-in-queue.
Having described the database location and names, how did you see it did not work if you recall?
If there’s a mostly relevant job database, looking in it might be an alternative to harder methods…
Or you can just wait and see, but figuring out the underlying cause of these issues would be best.
to see the advancement, Verbose level is enough, that’s the level where you see the number of blocks processed. Going for more verbosity only slows the processing further.
- Now 5 hours have passed, and the progress bar has moved a few %. That was not the case a few days ago, with the other version of Duplicati. So this looks promising!
- About backup size: As mentioned earlier:
" Last successful backup: 31/08/2023 (took 02:17:37)
Source: 364.23 GB
Backup: 460.54 GB / 18 Versions "
I have not scaled up block size. - I remember having problems with ‘database repair’! That’s why I do Recreate Database after drive image restore.
- About “Earlier I have moved the Duplicati database from the OS partition to the data partition, but that didn’t work.”
The problem was: When I did a drive image restore, Duplicati inflated my backup with about 70 GB of redundancy… (It happened twice.) - You say: “If there’s a mostly relevant job database, looking in it might be an alternative to harder methods…”
I haven’t the faintest idea what you are talking about… - I presume ‘Verbose’ is more verbose than ExplicitOnly and Profiling(!)
Now I will just wait and see how far it has reached tomorrow.
As I said with Verbose level watch out for messages such as
... processing blocklist volume xxx of yyy
that will allow you to estimate the remaining time, that is, if for example xxx =1000 and yyy = 5000 blocks, you have 20% of the job done.
No, Profiling add timing information, doubling the amount of logging compared to Verbose, and ExplicitOnly add yet a bit more logging to Profiling.
Now, finally, Recreate Database has finished, with this error message:
"Error while running Lenovo-Ubuntu
Recreated database has missing blocks and 18 broken filelists. Consider using “list-broken-files” and “purge-broken-files” to purge broken data from the remote store and the database."
I would like to do something drastic about my Duplicati backup… It’s not satisfactory that it contains about 150 GB of redundancy and that it takes days of almost 100% CPU use to Recreate Database - even with the optimized experimental version - 2.0.6.3_canary_2023-09-06.
You’ve used that word before, but what exactly do you mean by it?
There should be no redundant data blocks, as it’s all deduplicated.
If you meant you changed source and backup grew, that’s normal.
The amount of growth of course depends on a variety of factors…
Well, the slow recreate happens because the backend is heavily damaged. Not a missing file, corrupted files in a way that can’t be easily explained. This is new information because for years people have reported that recreate was taking weeks but no one was giving any precise info or followed on on their complaints.
Now that by a stroke of luck I have finally gathered from the flimsiest evidence the necessary information to change weeks into days of recreation, what we need is to take a peek inside the damaged files to have a chance of understanding how it can happen and possibly avoid it.
If no one bothers to help, no progress will be made. For the record, I have recently tried to recreate a 1.7 TB database that had no problems, it takes 45’ on a moderately powerful computer, there is no trouble with database recreation when the system is healthy.
In the past, when I restored a drive image of the Ubuntu OS partition, and Duplicati started backing up the data partition, it backed up all the files that had been created or changed there between creating the drive image backup and restoring it.
It even happened after trying to move the database to the data partition - where all the data I want to backup are. Therefore I concluded that the only way was to recreate the database after drive image restore.
In the weeks or months after the drive image restore maybe Duplicati removes some of the redundancy - I don’t know.
Shit! Now everything got worse… When duplicati tried starting the daily backup it stopped immediately with this error message:
" Error while running Lenovo-Ubuntu
The database was attempted repaired, but the repair did not complete. This database may be incomplete and the backup process cannot continue. You may delete the local database and attempt to repair it again. "
I guess I have to delete the whole backup (on the BackBlaze B2 server) and start from scratch…?!
Consider using “list-broken-files” and “purge-broken-files” to purge broken data
I ran the “list-broken-files” command, with a peculiar result. It’s a specific Thunderbird email folder 17 times, although on my data partition it doesn’t seem that I have changed that file since 15-09-2022. But I guess I better try to repair that file:
17 : 08/09/2022 18:16:26 (1 match(es))
/mnt/4AF15A0435E762B4/DataDoc/OneDrive/E-MAILS-TB-backup/bm6s7j0g.default/Mail/mail.unoeuro.com/Inbox.sbd/Inbox-2020 (1.08 GB)
16 : 16/10/2022 22:00:00 (1 match(es))
/mnt/4AF15A0435E762B4/DataDoc/OneDrive/E-MAILS-TB-backup/bm6s7j0g.default/Mail/mail.unoeuro.com/Inbox.sbd/Inbox-2020 (1.08 GB)
15 : 16/11/2022 21:00:01 (1 match(es))
/mnt/4AF15A0435E762B4/DataDoc/OneDrive/E-MAILS-TB-backup/bm6s7j0g.default/Mail/mail.unoeuro.com/Inbox.sbd/Inbox-2020 (1.08 GB)
14 : 27/11/2022 00:35:59 (1 match(es))
/mnt/4AF15A0435E762B4/DataDoc/OneDrive/E-MAILS-TB-backup/bm6s7j0g.default/Mail/mail.unoeuro.com/Inbox.sbd/Inbox-2020 (1.08 GB)
13 : 04/01/2023 19:44:54 (1 match(es))
/mnt/4AF15A0435E762B4/DataDoc/OneDrive/E-MAILS-TB-backup/bm6s7j0g.default/Mail/mail.unoeuro.com/Inbox.sbd/Inbox-2020 (1.08 GB)
12 : 12/02/2023 21:00:00 (1 match(es))
/mnt/4AF15A0435E762B4/DataDoc/OneDrive/E-MAILS-TB-backup/bm6s7j0g.default/Mail/mail.unoeuro.com/Inbox.sbd/Inbox-2020 (1.08 GB)
11 : 20/03/2023 21:00:00 (1 match(es))
/mnt/4AF15A0435E762B4/DataDoc/OneDrive/E-MAILS-TB-backup/bm6s7j0g.default/Mail/mail.unoeuro.com/Inbox.sbd/Inbox-2020 (1.08 GB)
10 : 25/04/2023 22:00:00 (1 match(es))
/mnt/4AF15A0435E762B4/DataDoc/OneDrive/E-MAILS-TB-backup/bm6s7j0g.default/Mail/mail.unoeuro.com/Inbox.sbd/Inbox-2020 (1.08 GB)
9 : 30/05/2023 22:00:00 (1 match(es))
/mnt/4AF15A0435E762B4/DataDoc/OneDrive/E-MAILS-TB-backup/bm6s7j0g.default/Mail/mail.unoeuro.com/Inbox.sbd/Inbox-2020 (1.08 GB)
8 : 09/07/2023 10:18:05 (1 match(es))
/mnt/4AF15A0435E762B4/DataDoc/OneDrive/E-MAILS-TB-backup/bm6s7j0g.default/Mail/mail.unoeuro.com/Inbox.sbd/Inbox-2020 (1.08 GB)
7 : 12/08/2023 15:17:52 (1 match(es))
/mnt/4AF15A0435E762B4/DataDoc/OneDrive/E-MAILS-TB-backup/bm6s7j0g.default/Mail/mail.unoeuro.com/Inbox.sbd/Inbox-2020 (1.08 GB)
6 : 20/08/2023 22:00:00 (1 match(es))
/mnt/4AF15A0435E762B4/DataDoc/OneDrive/E-MAILS-TB-backup/bm6s7j0g.default/Mail/mail.unoeuro.com/Inbox.sbd/Inbox-2020 (1.08 GB)
5 : 24/08/2023 22:00:00 (1 match(es))
/mnt/4AF15A0435E762B4/DataDoc/OneDrive/E-MAILS-TB-backup/bm6s7j0g.default/Mail/mail.unoeuro.com/Inbox.sbd/Inbox-2020 (1.08 GB)
4 : 26/08/2023 11:08:00 (1 match(es))
/mnt/4AF15A0435E762B4/DataDoc/OneDrive/E-MAILS-TB-backup/bm6s7j0g.default/Mail/mail.unoeuro.com/Inbox.sbd/Inbox-2020 (1.08 GB)
3 : 27/08/2023 12:25:55 (1 match(es))
/mnt/4AF15A0435E762B4/DataDoc/OneDrive/E-MAILS-TB-backup/bm6s7j0g.default/Mail/mail.unoeuro.com/Inbox.sbd/Inbox-2020 (1.08 GB)
2 : 28/08/2023 22:00:01 (1 match(es))
/mnt/4AF15A0435E762B4/DataDoc/OneDrive/E-MAILS-TB-backup/bm6s7j0g.default/Mail/mail.unoeuro.com/Inbox.sbd/Inbox-2020 (1.08 GB)
1 : 29/08/2023 22:00:01 (1 match(es))
/mnt/4AF15A0435E762B4/DataDoc/OneDrive/E-MAILS-TB-backup/bm6s7j0g.default/Mail/mail.unoeuro.com/Inbox.sbd/Inbox-2020 (1.08 GB)
0 : 30/08/2023 22:00:00 (1 match(es))
/mnt/4AF15A0435E762B4/DataDoc/OneDrive/E-MAILS-TB-backup/bm6s7j0g.default/Mail/mail.unoeuro.com/Inbox.sbd/Inbox-2020 (1.08 GB)
Return code: 0
I also ran the “purge-broken-files” command, and then manually started a backup. It added 95 GB (going from 460 GB to 555 GB). That seems like a lot, considering that it was less than 2 weeks ago I did the last backup before the drive image restore.
The backup took 5:42 hours:minutes. Normally backups take 10 minutes.
So I still don’t have much confidence in Duplicati… ![]()
More backed up data means more time spent backing up. I can’t say anything about file changes
without more information, but maybe you can see if normal returns now that restore got picked up.
Viewing the log files of a backup job has a big display of what was seen as changed, for example:
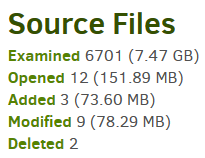
and Complete log button has a little bit more information. You can also run The COMPARE command.
I think the default versions are the most recent two, and if so you can see your multi-hour backup detail.
This is controlled by you, so specifically if space usage bothers you, change your retention settings on Options screen. Default keeps all versions, therefore usage builds up. Also don’t disable autocompact.
Compacting files at the backend is what releases space turned to waste from backup version deletions.
I just did a manual Compact. That didn’t help anything.
By the way: It was a long time ago I choose Smart Retention, and it’s still on.
I’d say you have some new data. You suspect it’s redundant. I suspect it’s not (at the block level).
You certainly have a lot of other tests suggested, but not done. I can even have you open the DB,
or you can take the approach you chose when we asked for Verbose log – instead, just wait a bit.
EDIT 1:
Another lightweight way to review the busy backup is to open Complete log, Copy log, paste it.
EDIT 2:
Not surprising. If you still have autocompact turned on, a manual will get no further than automatic.
The COMPACT command does have lots of adjustments, but it’s questionable if you want to tweak.
If you have an actual space shortage, fewer versions can help, smaller backup can help, and prune (carefully used because accidents are bad) can help. But the first step is to examine the situation…