Welcome to the forum @Silvio_Tavares
Also make sure that you didn’t greatly increase Remote volume size on Options page. See the note.

At default value, you’ll see roughly 50 MB files flowing through the Temp folder. The queue size is limited.
I’m not sure how the main drive would fill unless Temp space is very low or remote volumes very large…
That step is approximately the entire backup, isn’t it? Sometimes post-backup delete and compact takes time, but that wouldn’t happen on an initial backup, or is this a non-initial backup? They are typically faster because only changed data is backed up. A job log has statistics, and Complete log in it has even more.
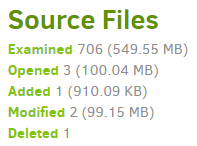
"BackendStatistics": {
"RemoteCalls": 26,
"BytesUploaded": 39560587,
"BytesDownloaded": 10514318,
"FilesUploaded": 18,
"FilesDownloaded": 6,
Going to Google Drive, beware of Google 750 GB daily upload limit, although maybe yours is less after compression. That and encryption add some time to the processing. Compression and deduplication happen based on a blocksize value that defaults to 100 KB, which means your roughly 1 TB backup is potentially making about 10 million blocks that are individually tracked. I suggest you raise that to 1 MB, however it can’t be done without starting the backup over, for reasons detailed (and being tested) here:
Why the heck CAN’T we change the blocksize?
Does this look like MBOX format? That might be deduplication-friendly. Is this Kerio Connect? What OS?
Be careful of “live” backups that might get an inconsistent view. I don’t know if the servers supports VSS.
For complex systems, sometimes it’s best to use dump tools provided by the system, then back that up.